
Using add-on components
The following sections describe optional add-on components for the Rackspace Private Cloud powered by VMware (RPC-VMware) product. These add-ons are not available as stand-alone products.
- Managed Backup for RPC-VMware
- Rackspace Hourly Database Application Services for RPC-VMware
- Disaster recovery
- Hybrid Cloud Extension
- Worldload domains
Managed Backup for RPC-VMware
The Managed Backup (MBU) service, which is an add-on component for RPC-VMware, provides image-based (snapshot) backups of the VMs provisioned in the the RPC- VMware environment. After configuration, the service backs up all discovered VMs on a daily basis and retains versions according to the retention policy that you select. The service also enables image-level restores of an entire VM so that your workload is recovered as quickly as possible.
The MBU add-on component is not available as a stand-alone product.
- Getting started with MBU for RPC-VMware
- MBU licensing
- MBU patching and upgrading
- MBU API
- Using MBU for RPC-VMware
- MBU glossary
Getting started with MBU for RPC-VMware
This section provides the following information about the Managed Backup (MBU) service for Rackspace Private Cloud powered by VMware (RPC-VMware).
- MBU architecture
- MBU components
- MBU features
- MBU roles and permissions
- MBU managed services
- MBU spheres of support
- MBU compatibility
- MBU authentication methods
MBU licensing
For details about licensing, see the main licensing section in the handbook.
MBU patching and upgrading
Rackspace patches and upgrades the Managed Backup (MBU) components as needed and schedules any maintenance operations with the customer that could cause disruption to the backup service.
For details about patching and upgrading RPC-VMware, see the main patching and upgrading section in the handbook.
MBU API
No API is provided for this product.
Using MBU for RPC-VMware
This section provides information about using the Managed Backup (MBU) add-on service for Rackspace Private Cloud powered by VMware (RPC-VMware).
MBU glossary
VM backup
A full image backup of a VM. No other backup options are offered.
VM restore
A full image restore of a VM. No other restore options are offered.
Successful VM backup
A backup job that completes successfully without error. It does not indicate that all files and applications were copied in a stable state.
Successful VM restore
A restore job that completes successfully without error. It does not indicate that all files and applications were restored to a stable state.
Rackspace Hourly Database Application Services for RPC-VMware
The Rackspace Hourly Database Application Services (DBA) enables you to leverage DBA expertise at Rackspace with 24x7x365 availability on a pay-as-you- go basis. Rackspace Hourly DBA Service is available for MySQL, Oracle®, and Microsoft® SQL Server® databases hosted on your RPC-VMware environment.
The Hourly DBA Service add-on component is not available as a stand-alone product.
The Rackspace Hourly DBA Service add-on component of RPC-VMware is designed to help you throughout the life cycle of your database. One key aspect of this service is the help that Rackspace can provide in the early stages of the application life cycle, where decisions might be crucial to the future of your application.
Rackspace DBA can help with the following items:
- Architecture
- Installation, configuration, upgrade, and migration
- Backup and recovery
- Database security
- Storage and capacity planning
- Performance tuning
- Troubleshooting
- Compatibility
Using the Hourly DBA Service for RPC-VMware
Customers can engage with the DBA team by creating a support ticket that describes the environment and the work being requested. The DBA team responds with either a request for more information or a quote for the time required to complete the job. Upon quote approval, the DBA team will begin its work.
Disaster recovery
The Disaster Recovery (DR) add-on for Rackspace Private Cloud powered by VMware (RPC-V) consists of two RPC-V environments in two different Rackspace data centers with the added components of VMware’s vSphere Replication and VMware’s Site Recovery Manager (SRM). vSphere Replication consists of up to 10 virtual appliances, the vSphere Replication Management Server (VRMS), and up to 9 vSphere Replication Servers, to share the replication traffic, scaled out as-needed. SRM consists of a single Windows VM with Site Recovery Manager installed. The VRMS and VRS(s) virtual appliances, as well as the SRM server, are deployed into the management resource pool of the RPC-V environment.
- Getting started
- vSphere Replication
- Configuring vSphere Replication
- Site Recovery Manager
- Spheres of support
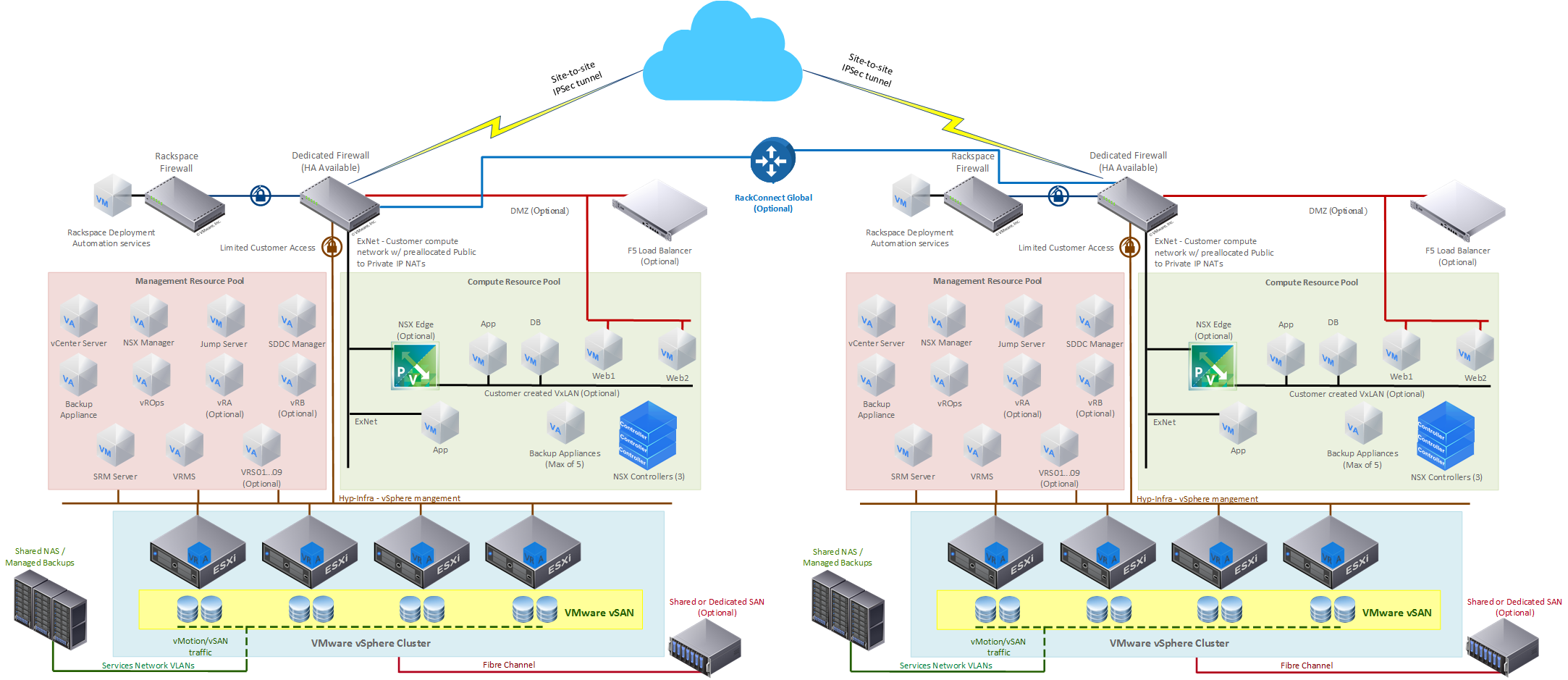
RPC-VMware disaster recovery architecture
The following diagram is a standard RPC-V DR configuration:
Getting started
What is Site Recovery Manager?
VMware Site Recovery Manager is an automation software that integrates with an underlying replication technology to provide policy-based management, non-disruptive testing, and automated orchestration of recovery plans. Site Recovery Manager is designed for virtual machines and protecting applications running in a VMware vSphere® environment.
To deliver flexibility and choice, Site Recovery Manager integrates natively with vSphere Replication™ leveraging the benefits of VMware vSphere. Site Recovery Manager also takes advantage of the Software-Defined Data Center (SDDC) architecture by integrating with other VMware solutions such as VMware NSX (network virtualization) and VMware vSAN (software-defined storage powering leading hyper-converged infrastructure solutions). By allowing users to test and automate the migration process of applications between sites at scale with minimal or no downtime, Site Recovery Manager fulfills the needs for a variety of use cases such as disaster recovery, disaster avoidance, planned data center migrations, site-level load balancing, and application maintenance testing.
Site Recovery Manager ensures fast and highly predictable recovery times, simplifies management through automation, and minimizes the total cost of ownership, making it the industry-leading solution to enable application availability and mobility across sites in private cloud environments.
Key features and capabilities
Traditional disaster recovery (DR) solutions that rely on manual processes often fail to meet business requirements because they are too expensive, complex, and unreliable. Site Recovery Manager automates every aspect of executing a recovery plan in order to accelerate recovery and eliminate the risks involved with manual processes. Organizations using Site Recovery Manager obtain the following features and benefits:
- Non-disruptive recovery testing – performs automated failover testing as frequently as needed in an isolated network to avoid impact to production applications and ensure regulatory compliance through detailed reports.
- Automated orchestration workflows – performs the DR failover or a planned migration, failback recovered virtual machines to the original site, and executes the same recovery plan with a single click.
- Automated recovery of network and security settings – Site Recovery Manager integrates with VMware NSX, eliminating the need to reconfigure IP addresses on recovered virtual machines. Security policies are also preserved, further reducing configurations post-recovery.
- Extensibility for custom automation – use the VMware vRealize® Orchestrator™ plug-in for Site Recovery Manager to build custom automation workflows. Prebuilt workflows simplify the process to get you started with custom workflow creation.
vSphere Replication
VMware vSphere Replication is a hypervisor-based, asynchronous replication solution for vSphere virtual machines. It is fully integrated with VMware vCenter Server and the vSphere Web Client. vSphere Replication delivers flexible, reliable, and cost-efficient replication to enable data protection and disaster recovery for all virtual machines in your environment.
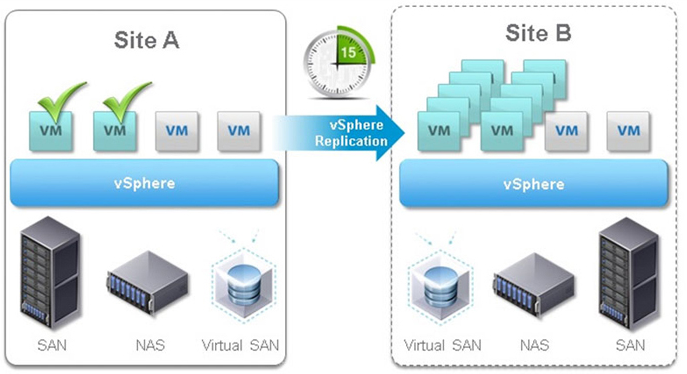
Hypervisor-based virtual machine replication
vSphere Replication is a deeply integrated VMware vSphere component. It is a robust hypervisor-based virtual machine replication engine. Any changes written to the running virtual machine’s virtual disk at the primary site are captured and sent to the secondary site. At the secondary site, the changes are applied to the virtual machine disks of the offline copy (replica) of the virtual machine.
Replication management
vSphere Replication includes an agent built into vSphere and one or more virtual appliances deployed by using vSphere Web Client. The agent tracks and sends changed data from a running virtual machine to a vSphere Replication appliance at a remote site; the appliance then adds the replicated data to the offline replica copy for that virtual machine. The vSphere Replication virtual appliance also manages and monitors the replication process. This gives administrators visibility into virtual machine protection status and the ability to recover virtual machines with a few clicks.
Replication configuration
Configuring replication for up to 2,000 virtual machines using vSphere Web Client doesn’t require a lot of steps: select one or more virtual machines, right-click on a virtual machine, and define the RPO and destination for its replica. vSphere Replication replicates the data to meet the Recovery Point Objective (RPO) at all times, ensuring that virtual machine content never ages past its defined replication policy. RPOs range from 5 minutes to 24 hours and can be configured on a per-virtual machine basis.
Virtual machine synchronization and seed copies
vSphere Replication can do an initial full synchronization of the source virtual machine and its replica copy. If desired, a seed copy of data can be placed at the destination to minimize the time and bandwidth required for the first replication. A seed copy of a virtual machine consists of a virtual machine disk file that can be positioned at the target location. A seed copy is manually created and placed at the recovery location by using any mechanism the administrator chooses, such as offline copying, FTP, an ISO image, or a virtual machine clone.
Intelligent transfers
After the initial full synchronization is complete, vSphere Replication transfers only data that has been altered. The vSphere kernel tracks unique writes to protected virtual machines, identifying and replicating only those blocks that have changed between replication cycles. This keeps network traffic to a minimum and allows for aggressive RPOs.
Non-intrusive replication
The virtual machine replication process is non-intrusive and takes place independently of the operating system or applications in the virtual machine. It is transparent to protected virtual machines and requires no changes to their configuration or ongoing management.
Configuring vSphere Replication
VMware vSphere Replication is integrated into the vSphere WebClient, allowing you to configure and manage replication on a per-VM basis.
To configure replication for a VM use the following steps:
-
Right-click on the VM you want to replicate.
-
Navigate to
All vSphere Replication Actions. -
Select
Configure Replication. -
This brings up the
Configure Replicationwizard. Use the following settings for each section:- Replication type: Replicate to a vCenter Server.
- Target site: The desired location, typically your target RPC-V environment.
- Replication server: Initially, auto-assign only load balances VMs to servers and will not proactively move VMs to new replication servers. You can choose to manually select the replication server if you have more than one.
- Target location: Click
Editto choose the target datastore for the VM(s). This can be done per-VM or in bulk. VMware recommends you have 2 times the available storage at the target side of the VM being replicated. If you’re using vSAN on the target side, you need to account for the protection level (Failures to tolerate [FTT] and Failure tolerance method) of the storage policy being applied to the VMDK at the target side. For example, if you have a VM consuming 100 GB, a FTT of 1 requires 400 GB free raw space on the vSAN datastore (100 GB x2 for vSphere Replication is 200 GB, FTT1 consumes twice as much on the vSAN datastore, thus 400 GB). vSAN displays available raw space without regard to FTT or Failure tolerance method because it is applied to the VM level and can differ per storage policy. Use the following to determine consumption on vSAN:- FTT1 with Failure tolerance method of RAID-1 consumes twice (2 times) the storage provisioned.
- FTT2 with Failure tolerance method of RAID-1 consumes triple (3 times) the storage provisioned (five-node cluster minimum required).
- FTT3 with Failure tolerance method of RAID-1 consumes quadruple (4 times) the storage provisioned (seven-node cluster minimum required).
- FTT1 with Failure tolerance method of RAID-5/6 consumes one and a third (1.3 times) the storage provisioned (four-node cluster minimum required).
- FTT2 with Failure tolerance method of RAID-5/6 consumes one and a half (1.5 times) the storage provisioned (six-node cluster minimum required).
Note: If you’re using VMFS storage, calculate consumption based on 2 times the storage provisioned for the VM.
This storage requirement is applied to both source and target VMs and datastores, as the source site could potentially become the target site in the event of a disaster.
-
Replication options
- Guest OS quiescing (Optional) - This option stuns or pauses the VM during a replication process to halt disk modifications in an effort to keep the replica consistent. It might impact running services within the guest, leverage Microsoft VSS for supported Windows OSs, and might require scripts for non-Windows OSs.
- Network compression (Optional) - This option might reduce throughput requirements for replication, but might impact RPO, as there will be higher CPU utilization to compress or decompress the data being replicated.
-
Recovery point objective (RPO) - The slider does not guarantee RPO and will generate a vCenter alert if RPO extends beyond the configured time. We do not recommend going below 15 minutes.
-
Point in time instances (Not supported in Managed DR for RPC-V) - You can configure the number of snapshots to retain during replication.
These instances will show up as snapshots on recovered VMs at the target site.
Warning: This can use drastically more storage at the target site as it functions similar to a snapshot retaining deltas.Note: Snapshot structure on the source-side VMs is not maintained and will be consolidated into the multiple point-in-time snapshots on the target side VM upon recovery. -
Monitor vSphere Replication
- In the vSphere WebClient, click the home icon and select
Hosts and Clusters. - Click the vCenter at the top of the left column.
- In the middle pane, click
Monitorand then selectvSphere Replication. - From there, you can select
Outgoing Replications,Incoming Replications, orReportsto see additional information.
- In the vSphere WebClient, click the home icon and select
-
Point in Time (PIT) instances (not supported in Managed DR)
- PIT retains replication instances as snapshots post-recovery, providing the ability to roll back to previous points in time of a recovered VM.
- We do not recommend enabling PIT instances, as this might have significant storage requirements and has the potential to fill up the datastore at the recovery site.
- If you choose to enable PIT instances, be sure to have a minimum of 4 times the amount (4x) of replicated data in free space at the recovery site.
Site Recovery Manager
VMware Site Recovery Manager (SRM) is a business continuity and disaster recovery (DR) solution that helps you to plan, test, and run the recovery of virtual machines between a protected vCenter Server site and a recovery vCenter Server site. You can use SRM to implement different types of recovery from the protected site to the recovery site.
- Planned migration is the orderly evacuation of virtual machines from the protected site to the recovery site. Planned migration prevents data loss when migrating workloads by replicating storage before and after shutting down all VMs and bringing them up on the recovery site. For a planned migration to succeed, both sites must be running and fully functioning.
- Disaster recovery does not require that both sites be up and running, for example if the protected site goes offline unexpectedly. During a disaster recovery operation, failure of operations on the protected site is reported but is otherwise ignored. After the protected site is online, re-running the recovery plan allows the sites to reestablish their connection and any failed recovery steps are rerun.
Planning
-
What apps should you protect?
- Business critical apps: Applications or servers that are essential to your company’s operation. Resist putting too many in this category to start with.
- Tier the applications and the supporting infrastructure to decide which should be recovered first.
- Remember not everything will be needed in disaster recovery. Some VM’s can be left out and restarted once the primary site is back online.
-
Where and how should you recover applications?
- Running Active/Active is often the preferred method. This allows for your applications to continue to run even if you lose one site. Running an Active/Passive method allows you to reduce the footprint of your target location if you intend to run less VMs or a higher consolidation ratio.
- In either method, you can use the idle resources to run your test, development, or certification environment.
-
Vendor support
- Before configuring SRM, you should consult with the software vendor to ensure supportability of the software by the vendor in the event of an SRM recovery operation.
-
IP customizations
SRM has the ability to change in-guest IP addresses based on subnets. This is a powerful tool to change subnets to match the target-side IP subnets.
- Pros:
- There is no requirement to stretch layer 2 subnets across sites (some network devices are incapable of this function, such as Cisco’s ASA).
- Allows all network subnets to be up and available at all times.
- Cons:
- When the OS boots and VM tools check in with vCenter, SRM will re-IP the guest OS and issue a reboot command, extending your recovery time.
- Might require application-specific connections to be modified for the new IP address.
- SRM cannot change IPs on virtual appliances without VM tools.
- Pros:
-
If you have the same subnets on both sites, you might not need to leverage this tool and can leave the in-guest IPs the same on either site.
- Pros:
- There is no requirement to reconfigure application connections during a recovery.
- Recovery times are faster as there isn’t a subsequent reboot post-IP change.
- Cons:
- The subnet on the target side will need to be shut to allow proper routing between the environments, requiring NetSec to not shut the subnet for testing or recovery.
- Recovery might happen quickly, but VMs will be isolated until network connectivity is restored.
Note
This relates to in-guest IP addresses only and does not change public IP addresses
- Pros:
Spheres of support
The Disaster Recovery add-on for Rackspace Private Cloud powered by VMware comes in two levels: Essential and Managed. Both levels are deployed with the same components and only differ only in how they are supported by Rackspace.
Essential
| Rackspace | Customer | |
|---|---|---|
| vSphere Replication deployment | ✔ | |
| vSphere Replication site pairing | ✔ | |
| SRM service monitoring | ✔ | |
| SRM installation | ✔ | |
| SRM site pairing | ✔ | |
| SRM inventory mappings(1) | ✔ | ✔ |
| SRM placeholder datastore | ✔ | |
| vSphere Replication - configure VM replication | ✔ | |
| vSphere Replication - service monitoring | ✔ | |
| vSphere Replication - monitor RPO | ✔ | |
| vSphere Replication - monitor VM status | ✔ | |
| vSphere Replication - stop VM replication | ✔ | |
| SRM - configure VM protection | ✔ | |
| SRM - configure VM boot priority | ✔ | |
| SRM - configure IP customization rules | ✔ | |
| SRM - configure protection groups | ✔ | |
| SRM - configure recovery plans | ✔ | |
| SRM - run recovery plan in test mode(2) | ✔ | |
| SRM - run recovery plan in planned migration mode(2) | ✔ | |
| SRM - run recovery plan in disaster recovery mode(2) | ✔ | |
| SRM - add VM to protection group | ✔ | |
| SRM - add VM to recovery plan | ✔ | |
| SRM - remove VM from protection group | ✔ | |
| SRM - remove VM from protection group | ✔ |
- Customer-created logical switches might need to be mapped to the recovery site.
- Additional Rackspace teams might need to be involved during Recovery Plan operations.
Managed
| Rackspace | Customer | |
|---|---|---|
| vSphere Replication deployment | ✔ | |
| vSphere Replication site pairing | ✔ | |
| SRM service monitoring | ✔ | |
| SRM installation | ✔ | |
| SRM site pairing | ✔ | |
| SRM inventory mappings(1) | ✔ | |
| SRM placeholder datastore | ✔ | |
| vSphere Replication - configure VM replication | ✔ | |
| vSphere Replication - service monitoring | ✔ | |
| vSphere Replication - monitor RPO | ✔ | |
| vSphere Replication - monitor VM status | ✔ | |
| vSphere Replication - stop VM replication | ✔ | |
| SRM - configure VM protection | ✔ | |
| SRM - configure VM boot priority | ✔ | |
| SRM - configure IP customization rules | ✔ | |
| SRM - configure protection groups | ✔ | |
| SRM - configure recovery plans | ✔ | |
| SRM - run recovery plan in test mode(2) | ✔ | ✔ |
| SRM - run recovery plan in planned migration mode | ✔ | |
| SRM - run recovery plan in disaster recovery mode(2) | ✔ | ✔ |
| SRM - add VM to protection group | ✔ | |
| SRM - add VM to recovery plan | ✔ | |
| SRM - remove VM from protection group | ✔ | |
| SRM - remove VM from protection group | ✔ |
- If required, notify Rackspace of any customer-created logical switches to create the network mapping.
- Additional Rackspace teams might need to be involved during recovery plan operations.
Hybrid Cloud Extension
VMware Hybrid Cloud Extension (HCX) is an all-in-one workload mobility tool. It enables migrations and cloud onboarding without the need to retrofit the source infrastructure by building an abstraction layer between on-premises data centers and the cloud. HCX supports migration from vSphere 5.0 and later without introducing application risk and complex migration assessments. With VMware HCX, the on-premises vSphere environment and cloud environments no longer need tightly coupled.
- Getting started
- HCX architecture
- HCX Components
- HCX Disaster Recovery
- HCX migration types
- Additional resources
Getting started
Use cases
HCX covers the following use cases:
- Hybridity services - Burst between on-premises and the private cloud
- Data center extension
- Data center evacuation
- Disaster recovery
Key capabilities
HCX provides the following capabilities:
- vSphere migrations with zero downtime
- Network extension and hybridity
- Scheduled migrations
- Disaster recovery and avoidance
Heterogenous network environments
Whether you have VXLANs, NSX for vSphere, NSX-T, or No NSX at all, each of these factors can complicate your migration plan. The good news is that HCX works by abstracting out the underlying network implementation, extending your networks from on-premises to the cloud seamlessly without the need for complex and time-consuming network re-architecture.
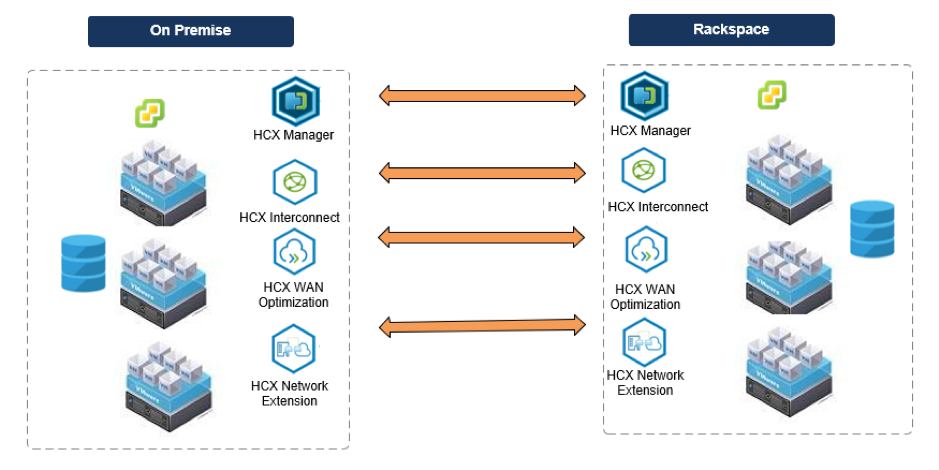
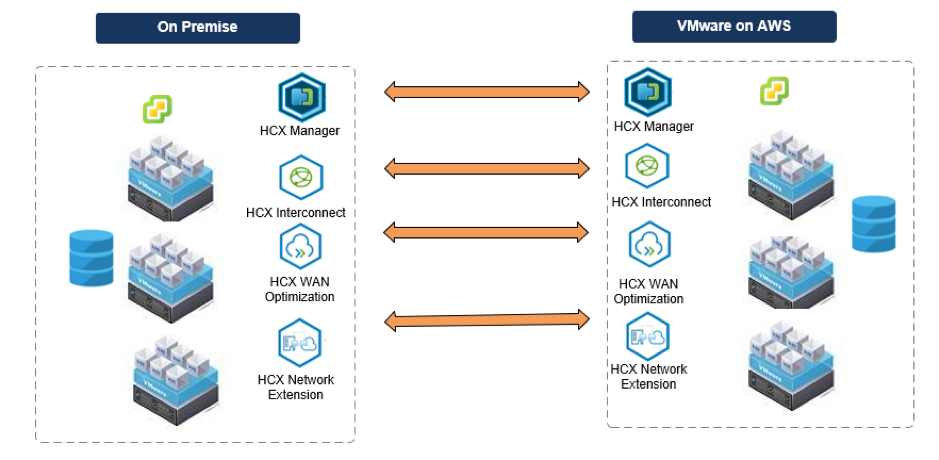
HCX architecture
The following diagram illustrates the HCX add-on architecture:
HCX Components
HCX is initially deployed as a virtual appliance, along with a vCenter plug-in that enables the HCX feature. After the HCX Manager virtual appliance is deployed, it is responsible for deploying the other appliances required for HCX. Mirror appliances are deployed at both the source and target locations. These deployments provide the capabilities outlined below.
HCX Manager
HCX Manager provides a framework for deploying the service appliances. The integration with vCenter allows HCX Operators to be authenticated, and allows tasks to be authorized by using the existing SSO identity sources. Hybridity actions can be initiated from the HCX manager via the HCX User Interface in vCenter and via virtual machine and distributed port group context menus.
HCX Interconnect
The HCX Interconnect service appliance provides replication and vMotion based migration capabilities over the Internet and private lines to the target site. The interconnect provides encryption, traffic engineering, and virtual machine mobility.
HCX WAN Optimization
The HCX WAN Optimization service improves performance characteristics of the VPN or Internet paths by applying WAN optimization techniques like data de-duplication and line conditioning. It accelerates onboarding to the cloud using Internet/VPN, without waiting for Direct Connect/MPLS circuits.
HCX Network Extension
The HCX Network Extension service provides a Layer 2 extension capability. The extension service permits keeping the same IP and MAC addresses during a Virtual Machine migration. Network Extension with Proximity Routing enabled ensures that forwarding between virtual machines connected to extended and routed networks, both on-premises and in the cloud, is symmetrical.
HCX Disaster Recovery
HCX Disaster Recovery is a service intended to protect virtual workloads managed by VMware vSphere that are either deployed in a private or a public cloud. HCX Disaster Recovery provides the following benefits:
- Asynchronous replication and recovery of virtual machines
- Optimized replication throughput by use of WAN optimizer
- Self service RPO settings from 5 minutes to 24 hours per virtual machine (VM protection with Host Based Replication)
HCX migration types
Cold Migration (offline)
This migration method uses the VMware NFC protocol. It is automatically selected when the source virtual machine is powered off.
vMotion (no downtime)
A live migration of a single VM at a time with no downtime. This is similar to a standard vSphere vMotion, and is most useful when migrating production critical VMs that have high availability requirements and zero downtime is desired.
vMotion and cold migration transfers a single virtual machine at one time. For example, if you plan to transfer 100 VMs, HCX will transfer each of these machines in a serial fashion; one transfer at a time. So while this method gives you the ability to rapidly migrate a VM, it doesn’t provide you with a mechanism to migrate VMs in bulk.
HCX Bulk Migration (low downtime)
This migration method uses the VMware vSphere Replication protocols to move the virtual machines to a remote site.
The Bulk migration option is designed for moving virtual machines in parallel.
This migration type can set to complete on a pre-defined schedule.
The virtual machine runs at the source site until the failover begins. The service interruption with bulk migration is equivalent to a reboot.
Cloud Motion with vSphere Replication (no downtime)
This is a relatively newer migration method currently available in preview for VMware Cloud on AWS. It combines the benefits of bulk migration (parallelism, scheduling, etc.) with the ability to migrate live workloads with no downtime.
- Uni-directional from on-premises to VMware Cloud on AWS
- Supports source vSphere (vCenter Server / ESXi) versions 5.5 and above
- Cross-version migration from vSphere 5.5 to the current release of 6.7 Update 1
- Currently no support for on-premises to on-premises migrations
- Concurrent migrations = 100 (initial data sync using vSphere Replication)
HCX Reverse Migration
This feature provides you the ability to migrate VMs from your cloud environment to your on-premises environment using vMotion, Cold, and Bulk migration methods. This is useful for situations in which it’s determined that a transferred VM–or set of VMs–isn’t suitable for the cloud.
Additional resources
To learn more about HCX, see the following resources:
Worldload domains
RPC-V uses VMware Cloud Foundation as the infrastructure deployment and lifecycle management platform, and therefore deploys a VMware Validated Design (VVD). Central to the VVD is the concept of a Workload Domain (WLD), which is a way to divide the software-defined data center (SDDC) into separate tenants. Each WLD has dedicated vCenters, NSX managers, and NSX controllers, but all WLDs in the same SDDC are joined together by using Enhanced Linked Mode, and therefore achieve a single pane of glass in the vCenter Console.
Workload domain use-cases
There are multiple use-cases for WLDs, such as running different types of service on each (such as VDI), achieving a higher degree of tenant separation compared to using clusters, and being able to patch different parts of the SDDC independently.
Workload domain architecture
The first WLD deployed in an SDDC is known as the Management Domain and runs all management components for all WLDs in the SDDC. All other WLDs are known as Infrastructure Workload Domains and only contain customer VMs.
The default architecture of RPC-V is a consolidated SDDC where management VMs and customer VMs share a single WLD by using separate vSphere Resource Pools. This architecture enables four-node clusters. Rackspace also allows customers to add additional WLDs to their SDDC. Such an architecture requires at least seven ESXi hosts, where the first four are dedicated to the management WLD, and a minimum of three hosts are for an Infrastructure WLD.
Updated 2 months ago