
Run:AI - Quickstart
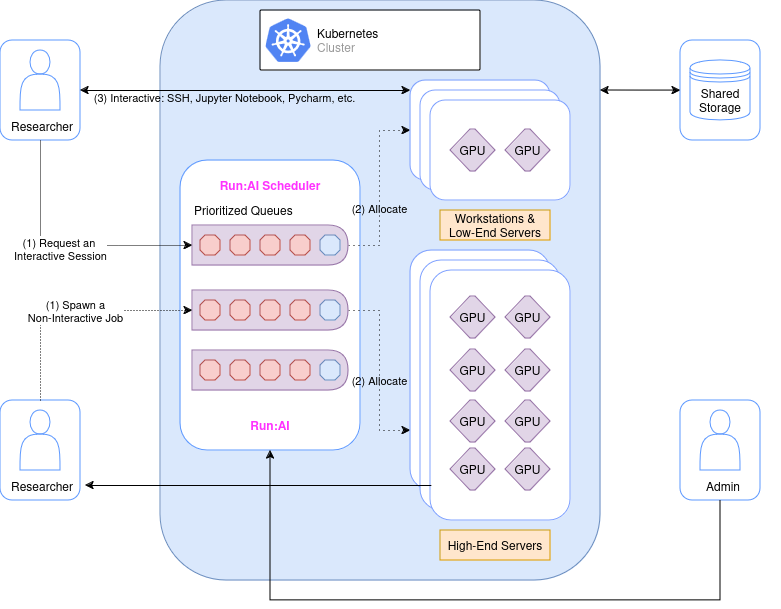
Run:AI's compute management platform accelerates data science initiatives by consolidating available resources and then dynamically assigning resources based on demand, thereby maximizing accessible compute power.
Log in to Run:AI using the Web UI
If you are currently not logged in to Run:AI and would like to use the Web UI, please follow these steps:
- Open your browser and navigate to https://<YOUR_HOSTNAME>.
- If prompted for your credentials, enter them or click on "Forgot Password?" if you have forgotten your password.
- Once logged in, you can submit jobs (in the "Workloads" pane), view currently allocated resources ("Overview" and "Analytics" panes), see your allocated projects and corresponding resources ("Project" pane), and much more.

Log in to Run:AI using the CLI
We have developed a small tool to install Run:AI and Kubernetes CLI tools, and included here you have the bash completion for both pieces of software, please set the hostname (include http or https) using the env variable RUNAI_HOSTNAME:
If you are using macOS (including Darwin and other versions), ensure that you have wget installed for the download to work. This was tested and implemented successfully using bash on Linux and macOS.
The tool, once downloaded and saved, should be executed as any other Bash script:
Choose the tool to be installed and the result should look like this:
Then, we create a ~/.kube folder in your $HOME directory and copy the "config" file shown here to ~/.kube/config (cp config ~/.kube/config).
First steps using the Run:AI CLI
If you are currently not logged in to Run:AI from your terminal, you can log in. First, install Run:AI as described in the previous section. Then, follow these steps:
In your terminal, run the command runai login and an URL will be printed in your terminal. Open this URL using your browser. Enter your credentials and click "Sign In".
You will see a token. Click on the copy button on the right. Paste the token into your terminal and press Enter.
Once you insert the token, you will see "INFO[0007] Logged in successfully" in your terminal.
If you are successful, the output should be similar to this example:
You can always check if you are logged in (or with which user you are logged in) by running:
You can now, for example, list the projects you are associated with by running:
We suggest you spend a few minutes to review the few available commands of Run:AI by running:
What are Projects on Run:AI
Researchers submit Workloads. To streamline resource allocation and prioritize work, Run:AI introduces the concept of Projects. Projects serve as a tool to implement resource allocation policies and create segregation between different initiatives. In most cases, a project represents a team, an individual, or an initiative that shares resources or has a specific resource budget (quota).
When a Researcher submits a workload, they must associate a Project name with the request. The Run:AI scheduler will compare the request against the current allocations and the Project's settings, determining whether the workload can be allocated resources or whether it should remain in the queue for future allocation.
Setting the Default Project:
In most cases, your projects will be assigned to you by your administrator, project manager, or the person in charge of the product. For the purpose of this documentation, we will exemplify the creation of a project by following these steps:
- Log in to the Run:AI Platform.
- Select "Projects" from the left menu.
- Click on the top-left button with the name "New Project."
After completing step 3, you will be presented with the following page:
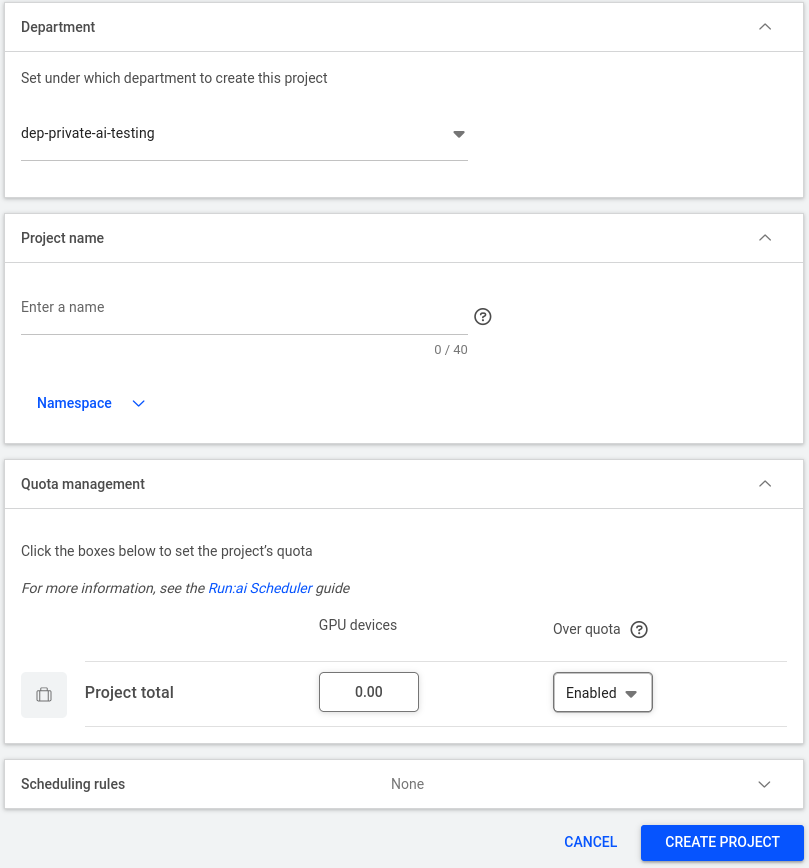
Proceed and fill in the "Project Name," create or select a Namespace if applicable, and then assign the desired amount of GPU devices under Quota Management, enabling Over quota if necessary.
Next, configure the Scheduling Rules, where you set the rules to control the utilization of the project's compute resources.
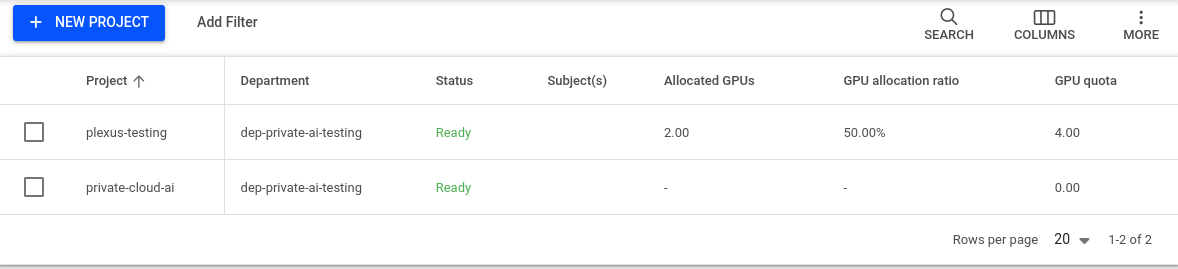
Upon creating a project, you will be redirected to the main project page. The "Status" column will display "Ready" once all creation tasks are completed, as demonstrated below:
Now, we can set the default project on the command-line interface using the "runai" command:
Resource Allocation in Run:AI
On a project level
Every project in Run:AI has a preassigned amount of resources, such as 1 GPU. Please note that we have a project overquota policy in place. This means that in practice, your project can use more resources than the assigned amount as long as the worker node assigned to your job is not fully utilized. Historically, the utilization of our virtual machines has been around 9% for GPU and 8% for CPU.
We guarantee that every researcher involved in a Run:AI project can use 0.2 GPUs at any time. This guarantee is subject to change to 0.1 in the future.
When a researcher requests more than the guaranteed 0.2 GPU, the corresponding jobs must be started using the --preemptible flag (a preemptible job).
Preemptible jobs can be scheduled above the guaranteed quota but may be reclaimed at any time if the worker node becomes overallocated (not before).
Preempted jobs are stopped (i.e., terminated) and restarted (from the pending state) once the resources become available again. Preempted jobs can have the following job statuses:
- Terminating: The job is now being preempted.
- Pending: The job is waiting in the queue again to receive resources.
For Run:AI "Training" jobs (In Run:AI, you have "Interactive," "Training," and "Inference" job types; see the link for more information), checkpointing can be used (storing the intermediate state of your training run):
If used, the job will continue (i.e., restart from the "Pending" state) from the last checkpoint. For more details on "Checkpoints," please refer to the section below.
Requesting GPU, CPU & Memory
When submitting a job, you can request a guaranteed amount of CPUs and memory by using the --cpu and --memory flags in the runai submit command.
The system ensures that if the job is scheduled, you will be able to receive the specified amount of CPU and memory. For further details on these flags see: runai submit.
CPU over allocation
The number of CPUs your workload will receive is guaranteed to be the number specified using the --cpu flag. However, in practice, you may receive more CPUs than you have requested. For example, if you are currently alone on a node, you will receive all the node's CPUs until another workload joins. At this point, each workload will receive a number of CPUs proportional to the number requested via the --cpu flag. For instance, if the first workload requested 1 CPU and the second requested 3 CPUs, then on a node with 40 CPUs, the workloads will receive 10 and 30 CPUs, respectively. If the --cpu flag is not specified, it will default to the cluster setting (see the "Memory Over-allocation" section below).
The amount of memory your workload will receive is also guaranteed to be the number defined using the --memory flag. Nonetheless, you may receive more memory than requested, which follows the same principle as CPU over-allocation, as described above.
Please note that if you utilize this memory over-allocation and new workloads join, your workload may encounter an out-of-memory exception and terminate. To learn how to avoid this, refer to the "CPU and Memory Limits" section.
Additionally, be aware that when you submit a workload with the --preeemptible flag, your workload can be preempted or terminated at any time. In this case, you will see the message "Job was preempted" in the runai logs output. To restart the workload, run "runai restart<workload_name>". Note that you can only restart a job that was preempted. If you stop a workload manually, you cannot restart it.
Memory over allocation
The allocated memory for your job is guaranteed to be the number specified using the --memory flag. In practice, however, you may receive more memory than you have requested. This is similar to the CPU over-allocation described earlier.
Please note, however, that if you have utilized this memory over-allocation and new workloads have joined, your job may encounter an out-of-memory exception and terminate.
CPU and Memory limits
You can limit the allocation of CPU and memory for your Job by using the --cpu-limit and --memory-limit flags in the runai submit command. For example:
The behavior of the limits differs for CPUs and memory.
Your Job will never be allocated with more than the amount specified in the --cpu-limit flag. If your Job attempts to allocate more than the amount specified in the --memory-limit flag, it will receive an out-of-memory exception. The limit (for both CPU and memory) overrides the cluster default described in the section below.
For further details on these flags, refer to the runai submit documentation.
Available Flags to Allocate Resources for Run:AI Workloads
You can go through the examples in the next section to test different job submission flags for resource allocation hands-on. Run runai help submit for details on available flags. Here is a part of the available flags related to Resource Allocation in Run:AI:
GPU-related flags:
--gpu-memory <string>: GPU memory that will be allocated for this Job (e.g., 1G, 20M, etc). Attempting to allocate more GPU memory in the job will result in an out-of-memory exception. You can check the available GPU memory on the worker node by runningnvidia-smiin the container. The total memory available to your job is circled in red in the example below.--gpu <float>or-g <float>: This flag is just an alternative for assigning GPU memory. For example, set--gpu 0.2to get 20% of the GPU memory on the GPU assigned for you. In general, the compute resources are shared (not the memory) on a worker node when using fractions of a GPU (not when allocating full GPUs).--large-shm: When you run jobs with > 1 GPU, add this flag on job submission. This allocates a large/dev/shmdevice (large shared memory) for this Job (64G). In case you don't use this flag with GPU > 1, you will get an error: ERROR: Unexpected bus error encountered in worker. This might be caused by insufficient shared memory (shm).
To learn more about GPU allocation, follow this part of the Run:AI documentation.
Note that if you only specify -g <float> and no memory requirements, the GPU RAM is allocated proportionally to available hardware GPU RAM: E.g., with -g 0.1, you will get 10% of total GPU RAM. (The total GPU ram of an A30 is 24GB).
CPU-Related Flags
--cpu: The number of CPUs your job will receive is guaranteed to be the number defined using the --cpu flag. However, you may receive more CPUs than you have requested in practice:
-
If you are currently the only workload on a node, you will receive all the node's CPUs until another workload joins.
-
When a second workload joins, each workload will receive a number of CPUs proportional to the number requested via the
--cpuflag. For example, if the first workload requested 1 CPU and the second requested 3 CPUs, then on a node with 40 CPUs, the workloads will receive 10 and 30 CPUs, respectively.
--memory <string> : The guaranteed (minimum) CPU memory to allocate for this job (1G, 20M). In practice, you will receive more memory than the minimum amount if it is currently available on the worker node.
If your job does not specify --cpu, the system will use a default value. The default is cluster-wide and is defined as a ratio of GPUs to CPUs.
For example, we currently have a total of 6 GPUs and 384 CPUs with 3TB of RAM in runai. Check the runai GUI "Analytics" pane for up-to-date values under the "Workloads" section or execute runai top nodes:
Learn more about CPU and memory allocation in the following sections of the Run:AI documentation.
Note that any Run:AI job cannot be scheduled unless the system can guarantee the defined amount of resources to the job.
Persistent storage (Data Source)
How to access Data Sources? click on the main menu, at the botton, next to Templates.
A data source is a location where research-relevant data sets are stored. The data can be stored locally or in the cloud. Workspaces can be attached to multiple data sources for both reading and writing.
Run:AI supports various storage technologies, including:
- NFS
- PVC
- S3 Bucket
- Git
- Host path
Creating a PVC Data Source
To create a Persistent Volume Claim (PVC) data source, please provide the following:
- Scope (cluster, department, or project) that will be assigned to the PVC and all its subsidiaries. This scope determines the visibility and access control of the PVC within the Run:AI environment.
- A data source name: This will be used to identify the PVC in the system.
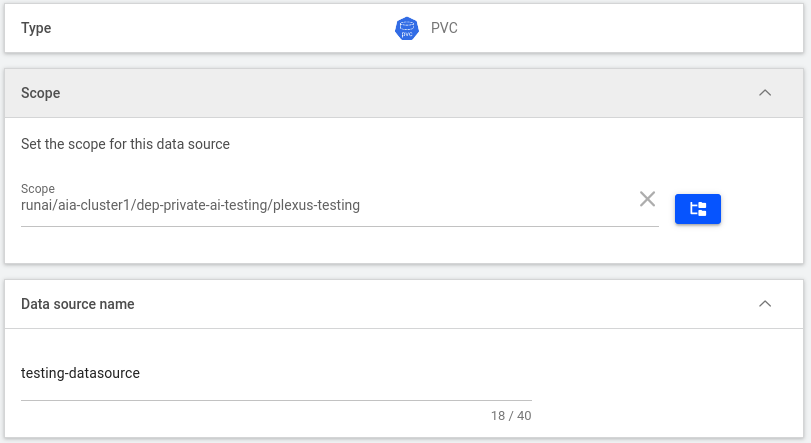
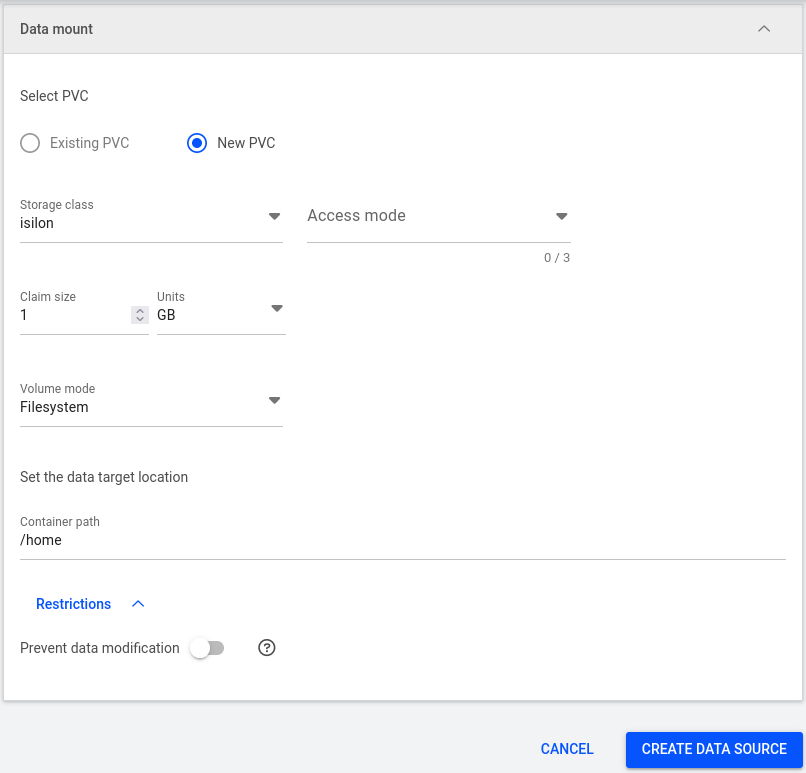
Select an existing PVC or create a new one by providing:
- A storage class
- Access mode
- Claim size with Units
- Volume mode
- The path within the container where the data will be mounted
- Restrictions to prevent data modification
Example image:
How do i integrate a PVC with Run:AI on the CLI?
As you can see in the example provided, this is done using kubectl to obtain the full name of the Persistent Volume Claim (PVC).
Then, you can construct your command line as follows:
Copying Files to and from Kubernetes Pods
Kubernetes & Docker images in Run:AI
- Every Run:AI workload is started from a docker image.
- You select the image you want to use by specifying the --image/-i <image> flag.
Most used Docker images related to Machine Learning/AI
By default, images are pulled from Docker Hub. For example:
- The official Triton Server image can be pull with --image nvcr.io/nvidia/tritonserver:24.04-trtllm-python-py3
- The official TensorTR image can be pull with --image nvidia/cuda:12.4.0-devel-ubuntu22.04
- The official vLLM with OpenAI style endpoint can be pull with --image vllm/vllm-openai
- The official Ubuntu image can be pull with --image ubuntu
- The official Alpine image can be pull with --image alpine
- The official Jupyter/base-notebook can be pull with --image jupyter/base-notebook
- The official TensorFlow can be pull with --image tensorflow/tensorflow
Troubleshooting Workloads
To debug a crashed container(job or workload), try the following:
Get your job status by running:
Because the type of workload launched to perform a single task, it will generate the container and then be marked as completed on our Run:AI UI, ensuring no errors occur:

You could also catch the output logs by using the runai logs <workload>:
There are several options available for the logs sub-command:
Step by Step examples
Running your first workload
Deploy Ubuntu with CPU only
In this example, we will start a Run:AI job (only cpu, no gpu) in your preferred terminal.
Run the following command in your terminal:
Explanation of the above command:
-i ubuntu: the image you want to use. If no full address is specified -as here- the image is searched in the registry on dockerhub, specifically for the ubuntu image.--cpu 4: Optional. This will ensure that you get 4 CPU's allocated for your job. In practice, you will receive more CPU's than the minimum amount if currently available on the worker node.--attach: attach directly to the container after starting it.--interactive: Mark this Job as interactive, meaning, it can run indefinitely and will not be preempted by other jobs. In case you don't specify--interactivethe job is assumed to be a training job that a) can be preempted and b) is terminated once all execution steps are finished in the container.
Once you started your job, you will see the message "Waiting for pod to start running..." for about 5-10 seconds and finally "Connecting to pod ubuntu-0-0". In this specific example, you are automatically connected to the container since you used --attach.
In case you are not automatically connected to your container or want to learn to connect/reconnect to a container, read the next subsection "Connecting to your container". Once your container has started, you will be directly connected to it.
Your PROMPT will change to container shell:
Connecting/Reconnecting to your container
There are several reasons why you might not have been connected to your container. For example, 'Timeout waiting for job to start running' occurs for large images that take a long time to download.
In case you want to connect or reconnect to your container from your terminal, run:
In case your container has a TTY. While most images allocate a TTY, you can allocate a TTY manually for any Run:AI jobs by specifying --tty with runai submit.
In case your container has the Bash command available, you can connect/reconnect by running:
You can also connect or reconnect using kubectl, the Kubernetes command-line interface, without utilizing RunAi, by executing the following command:
In all the mentioned cases, replace <workload_name> with your desired job name. For example, use "ubuntu" for the current job, and replace <project> with your project name, such as "plexus-testing." Please note that in Run:AI, your workload will have the job name "ubuntu." When using the kubectl command, the name of your container will always be the Run:AI workload name followed by "-0-0."
Consequently, your Run:AI container with the workload name "ubuntu" will be referred to as "ubuntu-0-0" when using the kubectl command.
Congratulations! You have successfully started your first Run:AI container.
Exiting a workload in Run:AI
If you type "exit" within the container, you will exit the container and, in this case, terminate the Run:AI job (the container hosting the session). A persistent container example is shown further below. Please note that "training" jobs (as opposed to "interactive" jobs) will persist until they are finished (or terminated by the user or preempted by the system in case they exceed their quota).
To verify that your job is no longer running and has a status of "Succeeded" (or "Failed," which is also acceptable), wait for at least 2-3 seconds after exiting the container and then run:
Note that as long as you see your job with the name "ubuntu" in the list above, you cannot create a new job with the same job name "ubuntu." To remove the job from the list, run:
This will make it possible for you to submit a new job with a different job name. Alternatively, you can choose a different job name altogether.
To delete all of your jobs, run:
Other examples
Deployment of vLLM
Depending on whether you have a PVC (Persistent Volume Claim) created or not, the deployment should be pretty straightforward. For this example, we will deploy via the Web UI and then use kubectl with YAML:
How to Submit a Workload
To submit a workload using the UI, please follow these steps:
- In the left menu, click on "Workloads."
- Click on "New Workload," and then select "Inference."
Then a new page will be presented similar to this one:
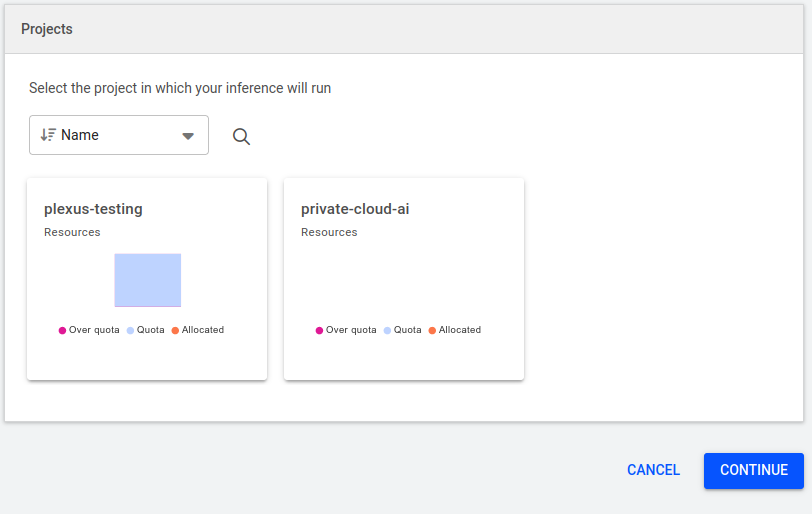
Inference for vLLM
In the Projects pane, select a project. Use the search box to find projects that are not listed. If you cannot find the project, consult your system administrator.
When you select your Project, a new dialog will be displayed as "Inference name":
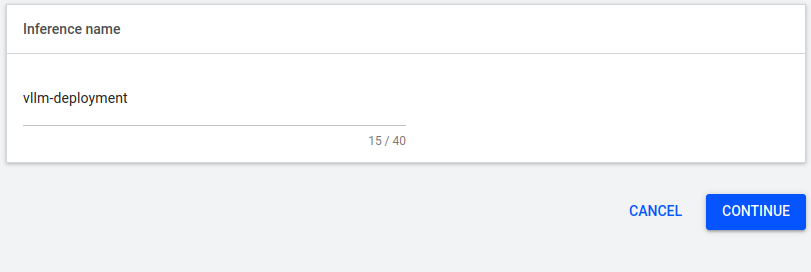
When you click on continue:
- In the Inference Name field, enter a name for the workload, in this case, vllm-deployment.
- In the Inference Name field, enter a name for the workload, in this case,
vllm-deployment. - In the Environment field, select an environment. Use the search box to find an environment that is not listed. If you cannot find an environment, press New Environment or consult your system administrator.
- In the Set the Connection for Your Tool(s) pane, choose a tool for your environment (if available).
- In the Runtime Settings field, set commands and arguments for the container running in the pod (optional).
- In the Environment Variable you should have set
vllm/vllm-openai:v0.5.0for your image.- For the Runtime Settings we should add the following:
- Set a command and arguments for the container running in the pod:
- Command:
python3 - Arguments:
-m vllm.entrypoints.openai.api_server --model NousResearch/Hermes-2-Pro-Mistral-7B --dtype=half --tensor-parallel-size 2 --served-model-name gpt-3.5-turbo --enforce-eager --max-model-len 16384
- Command:
- Set the environment variable(s)
NCCL_P2P_DISABLEset to1
- Set the container's working directory if required.
- Set a command and arguments for the container running in the pod:
- For the Runtime Settings we should add the following:
- Press Create Environment.
- In the Compute Resource field, select a compute resource from the tiles. Use the search box to find a compute resource that is not listed. If you cannot find a compute resource, press New Compute Resource or consult your system administrator.
- In the Replica Autoscaling section, set the minimum and maximum replicas for your inference. Then select either Never or After One Minute of Inactivity to set when the replicas should be automatically scaled down to zero.
- In the Nodes field, change the order of priority of the node pools, or add a new node pool to the list.
- Press Create Inference when you are done.
NoticeData sources that are unavailable will be displayed in a faded (gray) color.
Assets currently undergoing cluster synchronization will also be displayed in a faded (gray) color.
Only the following resources are supported: Pod Visualizer Charts (PVC), Git repositories, and Configuration Maps.
Follow your job status with the describe verb as show here:
If successful, you will see an output similar to this one:
Then, call the model list and inference using cURL:
Launching Jupyter Lab/Notebook with Port Forwarding on Run:AI
Using the same method described in "How do I integrate a PVC with Run:AI on the CLI?", we execute the command-line command by appending --service-type=nodeport --port 30088:8888.
Because the image isn't prepared for Jupyter Lab or the Notebook itself (we use a Finetune prepared image), I would proceed to install the required packages for the application as follows:
After the installation, we can execute Jupyter in the following manner:
Now, we forward the port in another terminal using the job name provided by Run:AI (by executing the command "runai list jobs").:
Now, simply enter the address into your browser as shown below (Tree View):
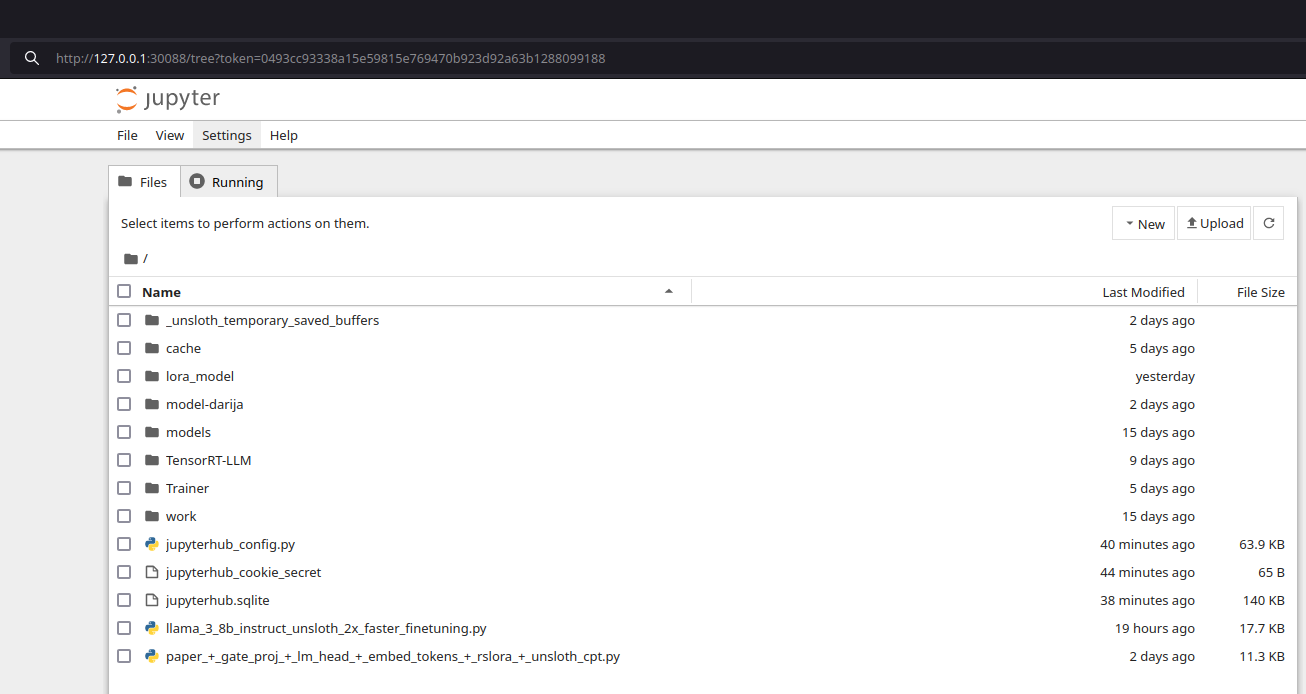
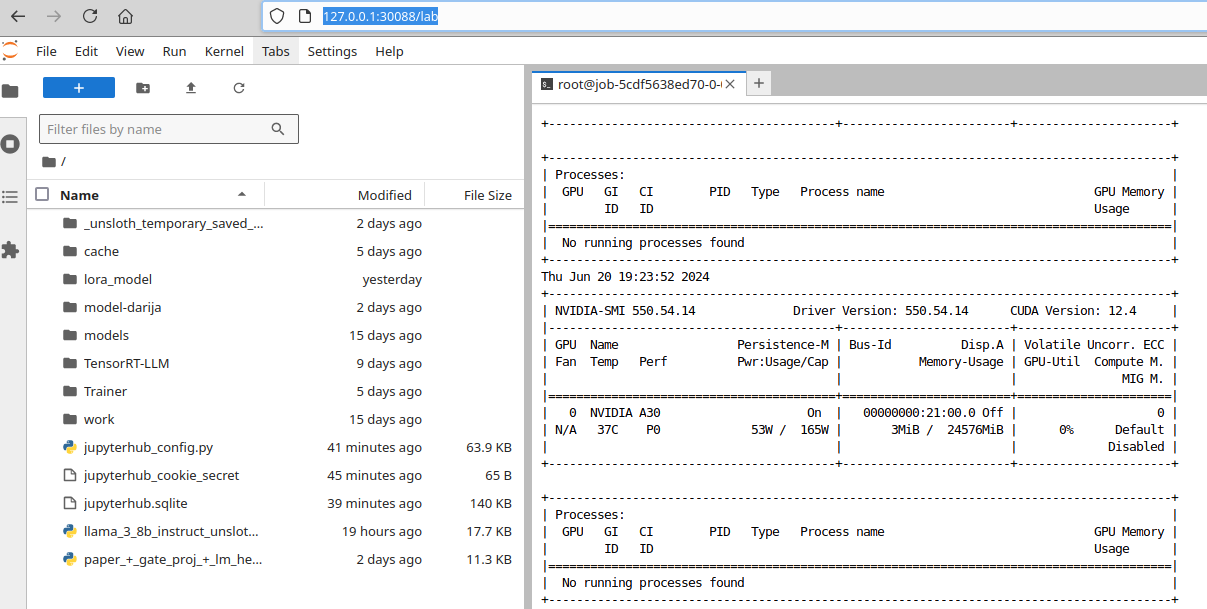
Or replace tree on the URL with Lab:
Run:AI Supported Integrations
Third-party integrations are tools that Run:ai supports and manages. These are tools typically used to create workloads tailored for specific purposes. Third-party integrations also encompass typical Kubernetes workloads.
Notable features of third-party tool support include:
- Airflow: Airflow™ is a scalable, modular workflow management platform that uses a message queue to orchestrate workers. It allows for dynamic pipeline generation in Python, enabling users to define their own operators and extend libraries. Airflow™'s pipelines are lean and explicit, with built-in parametrization using the Jinja templating engine.
- MLflow: MLflow is an open-source platform specifically designed to assist machine learning practitioners and teams in managing the intricacies of the machine learning process. With a focus on the entire lifecycle of machine learning projects, MLflow ensures that each phase is manageable, traceable, and reproducible.
- Kubeflow: Kubeflow is a project aimed at simplifying, porting, and scaling machine learning (ML) workflows on Kubernetes. It provides a way to deploy top-tier open-source ML systems to various infrastructures wherever Kubernetes is running.
- Seldon Core: Seldon Core is a software framework designed for DevOps and ML engineers to streamline the deployment of machine learning models into production with flexibility, efficiency, and control. It has been used in highly regulated industries and reduces complications in deployment and scaling.
- Apache Spark: Apache Spark is a versatile analytics engine designed for large-scale data processing. It offers APIs in Java, Scala, Python, and R, along with an optimized engine for executing general execution graphs. It includes various high-level tools such as Spark SQL for SQL and structured data processing, pandas API for pandas workloads, MLlib for machine learning, GraphX for graph processing, and Structured Streaming for incremental computation and stream processing.
- Ray Serve: Ray is an open-source, unified framework designed for scaling AI and Python applications, including machine learning. It offers a compute layer for parallel processing, eliminating the need for expertise in distributed systems. Ray simplifies the complexity of running distributed individual and end-to-end machine learning workflows by minimizing the associated complexity.
Updated 8 months ago