
Replication and Recovery
Rackspace Technology offers add-on options that help you recover your VMs, including:
- Periodic VM backup
- Continuous VM replication
This chapter contains the following sections:
Understanding VM replication
VM Replication Enhanced Edition, powered by the Zerto® IT Resilience Platform™, delivers a fully managed always-on experience. With Recovery Point Objectives (RPOs) and Recovery Time Objectives (RTOs) measured in seconds and minutes, VM replication provides near-continuous storage-agnostic data replication enabling the recovery of VMs from business-impacting events such as ransomware, hardware failures, or natural disasters. VM Replication offers both local and remote replication.
This section includes the following topics:
- Understanding VM replication key features
- Understanding VM replication architecture
- Understanding how VM replication protection works
- Understanding Remote Edition Initial Synchronization
- Understanding Remote Edition Continuous Replication
- Understanding VPGs
- Understanding test operations
- Understanding failover operations
- Understanding VM replication roles and responsibilities
You cannot configure VMs that have one of the following characteristics for a source VM:
- Active Directory VMs (We support and recommend Active Directory native replication.)
- VMs with raw device mappings (RDMs).
- Multi-write disk mode.
- Oracle clusters.
- RHEL clusters.
Understanding VM replication key features
VM Replication includes the following features:
- Continuous replication: Deliver an always-on customer experience.
- Hypervisor-based block-level replication
- Outages and disruption: Protect your brand from all disruptions.
- Continuous data protection provides RTO and RPO measured in seconds and minutes.
- Complete automation and orchestration of recovery with no manual steps
- Simplicity with failover and failback in only three clicks.
- Ransomware attacks: Avoid ransomware cost, data loss, and downtime.
- Point-in-time recovery for seamless roll-back to moments before the attack.
- Journal provides rewind capability in near real-time increments for up to seven days, by default.
- Complete data protection: One platform for all your data protection needs.
- Automated testing to ensure recoverability with no impact to production.
- Reports for full compliance that are consistent with regulations like Health Insurance Portability and Accountability Act (HIPAA), Payment Card Industry (PCI), and General Data Protection Regulation (GDPR)
Understanding VM replication architecture
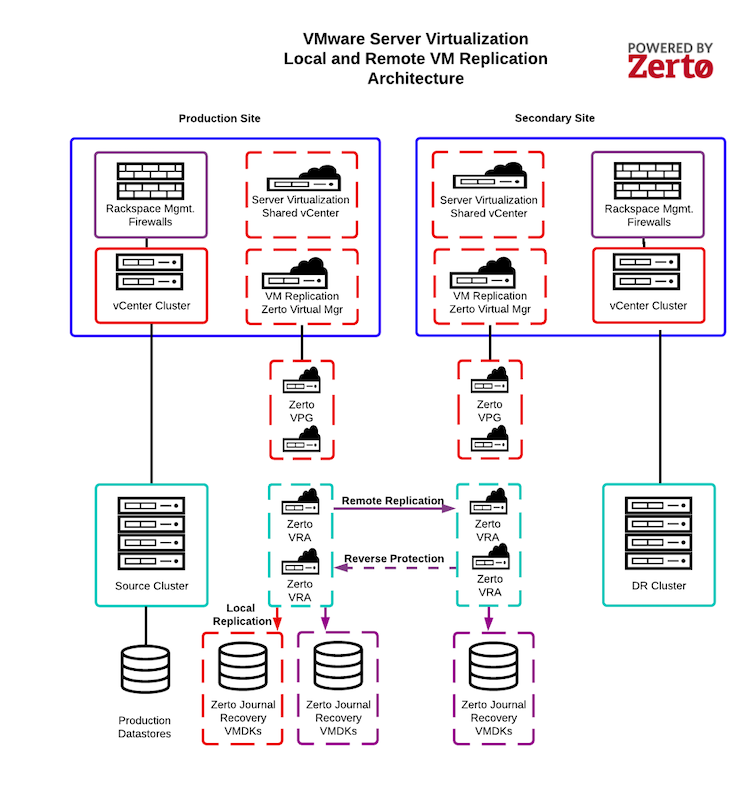
The following diagram illustrates the VM Replication architecture, including the following key components, as defined by the Zerto IT Resilience Platform documentation:
Zerto Virtual Manager (ZVM): The ZVM manages everything required for replicating between the source and target sites except for the actual replication of data. The ZVM is deployed in the Rackspace Technology management infrastructure and interacts with the vCenter Server to inventory the VMs, disks, networks, hosts, and so on. The ZVM also monitors changes in the VMware environment and responds accordingly. You do not have access to any components of the Rackspace Technology management infrastructure.
Zerto Virtual Replication Appliance (VRA): The VRA is a VM that manages the replication of protected VM writes across sites. Install a VRA on every hypervisor that hosts VMs that require protection in the source site and on every hypervisor that hosts the replicated VMs in the target site. You do not have access to the VRA.
Zerto Virtual Protection Group (VPG): The VPG groups VMs for replication purposes. For example, you should replicate all VMs that comprise an application, such as the database, application server, and web server, to maintain data integrity. VPGs allow you to protect, recover, and test VMs together.
Zerto Journal: While processing transactions on the source site, VRA intercepts every write to a protected VM and sends a copy of the write, asynchronously, to the target site. The target site adds the write to a journal managed by the VRA. Each protected VM has its own journal. By default, the Zerto Journal is located on the Target VM recovery datastore. Each journal can expand to a size specified in the VPG definition and automatically shrinks when the expanded capacity is not needed.
Understanding how VM replication protection works
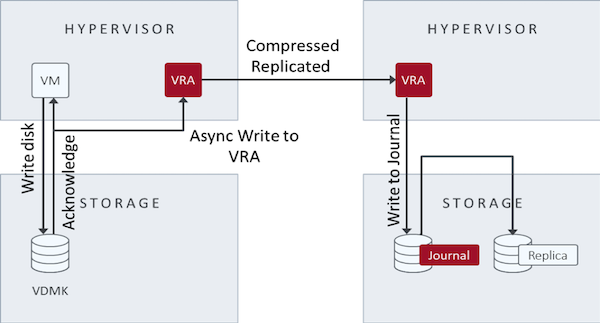
With Zerto’s hypervisor-based continuous data replication, Zerto copies every write to the VM and sends it, asynchronously, to the target site. At the same time, the source site continues to process the write.
On the target site, Zerto writes the write to a journal managed by the Zerto Virtual Replication Appliance (VRA). Each protected VM has a unique journal. Every few seconds, the system writes a checkpoint to each journal. These checkpoints ensure write-order fidelity and crash-consistency to each checkpoint. During recovery, one of the crash-consistent checkpoints is selected and recovered to this point.
The Zerto VRA manages the journals for every source VM to be recovered to the hypervisor hosting that VRA. It also manages the images of the protected volumes for these target VMs. During a failover, you can specify that you want to recover the source VMs in the VPG by using the last checkpoint. Alternatively, you can specify an earlier checkpoint, in which case the system synchronizes the recovery of the mirror images under the VRA to the chosen checkpoint. Thus, you can recover the environment to the point before any corruption and ignore later corrupted journal writes. The cause of the corruption, such as a crash in the source site or a ransomware attack, does not affect the recovery process.
Understanding remote edition initial synchronization
After you define a VPG, the system updates the Zerto VRA in the target site with information about the VPG. Then, it synchronizes the data on the source VMs with the target VMs managed by the VRA on the target site.
For the synchronization to work, ensure that the source VMs are turned on. To synchronize across the sites, the Zerto VRA requires an active input-output (IO) stack to have access to the VM data. If the VM is not running, there is no IO stack to use to access the protected data for replication to the target site recovery disks.
The synchronization process can take some time, depending on the size of the source VMs, the amount of data in its volumes, and the bandwidth between the sites. During this synchronization, you cannot perform any replication task, such as failover operations.
Initial synchronization can cause a spike in bandwidth usage and might result in bandwidth overage charges.
After synchronization completes, the VRA on the target site includes a complete copy of every VM in the VPG. At this time, the source VMs in the VPG are fully protected, and the system sends the delta changes on these VMs to the recovery site.
Understanding remote edition continuous replication
After the initial synchronization, Zerto copies every write to a source VM to the target site. At the same time, the source site continues to process the write and sends the copy asynchronously to the target site, where the system writes it to a journal managed by a Zerto VRA. Each protected source VM has a unique journal.
In addition to the writes, every few seconds, the system updates all journals with a checkpoint timestamp. These checkpoints ensure write-order fidelity and crash-consistency. You can recover to the last checkpoint or a user-selected, crash-consistent checkpoint. The choice of recovery point enables you to recover the source VMs to either the last crash-consistent point-in-time or a point-in-time before a ransomware attack.
The system writes data and checkpoints to the target VM’s Zerto Journal until the specified journal history size is reached, which is the optimum situation. At this point, while new writes and checkpoints are written to a journal, the older writes are written to the target VM recovery virtual disks. When you specify a checkpoint to recover to, the checkpoint must still be in the journal. For example, if the journal’s history is seven days, you can specify recovery to any checkpoint within the previous seven days. After the time specified, the system updates the mirror virtual disk volumes (VMDK) maintained by the Zerto VRA.
Initial synchronization can cause a spike in bandwidth usage and might result in bandwidth overage charges.
The following image illustrates continuous data replication:
Understanding VPGs
A Virtual Protected Group (VPG) enables you to protect, recover, and test VMs together while maintaining write-order fidelity. The Zerto VPG must include at least one VM. After Rackspace Technology creates the default VPG, you can tell us how to group your source VMs into VPGs. Consider the following examples:
Group by customer: If you host a set of VMs in VMware Server Virtualization for each of your customers, you can create a VPG for each customer. This configuration ensures that you maintain write-order fidelity across all VMs.
Group by workload or application: If you host multiple workloads or applications, you can group your VMs by each workload or application. For example, for your production application, which comprises a database, application, and web server, you can group VMs into a single VPG to ensure write-order fidelity across all three tiers.
All the VMs in a VPG must reside in the same VMware vCenter.
VPG Properties
For each Source VM, you need to provide Rackspace Technology the following properties:
- VPG name: The VPG name conforms to the following naming convention:
Account ID – Journal History Days – VMs
You can replace the VM value in the VPG name with a customer-defined name. Defining the appendix helps you identify the contents of the VPG.
For example, if you group VMs by customers, use the customer name or ID. If you group VMs by application or workload, use a descriptor, such as ProdCRM, to represent your Production CRM application.
- Journal history days: The target length of time you can roll back VMs within a VPG upon recovery.
By default, each VM has a value of seven days. Setting the Zerto Journal History to seven days provides the ability to specify a recovery point-in-time within the last seven days.
For example, if you accidentally decommission the wrong VMs and need to recover the VMs, but it takes you five days to identify the mistake, you can select the checkpoint before the decommission because you have a seven-day journal full of checkpoints.
The actual journal history size depends on the available storage. Configuring longer journal history requires the storage capacity to keep all changes for the desired period. The configured target might not be met, and journal checkpoints that have not met the desired journal history target might be automatically deleted if there is insufficient space.
- Boot order: The order in which the VMs contained within a VPG boot upon recovery. VMs boot in ascending order.
For example, suppose the VPG includes a database, application tier, and web server tier, and the database must be available before the application tier or web server. In that case, you can set the database boot order to 1, application tier to 2, and web server to 3.
- Failover IP range:
- Private: By default, and subject to availability, when a VM fails over to the target site, we set the private IPs to match the source IPs. You can customize this to a different IP.
- Public: When a VM fails over to the target site, its public IP address is automatically changed. Public Blocks are assigned out of the target site location.
Understanding test operations
We recommend that you periodically test the replication capabilities to ensure that the replication is working as expected. To begin planning a test, open a ticket with Rackspace Technology. During a test, the target VMs are powered on.
You have the following networking options for VMs that are tested on the secondary site. These options are pre-defined in the VPG settings:
- Use live production target site networks: By default, live recovery networks are used. If the VMs are configured to use live networks, you might be able to access them, but it might also be required to temporarily suspend site-to-site VPN, depending on the configuration. This are the same networks that are used during a true failover.
If you want to use one of the following options, open a Rackspace Technology ticket.
- Use dedicated testing networks with limited connectivity: This option shares some elements of the live production target site networks and the bubble networks. Separate testing networks are set up that allow you to access the VMs, but the VMs have limited outside connectivity. You can work with us to define the connectivity rules.
- Use bubble network: If the VMs are configured to use a bubble network, you won’t be able to access them. However, we verify via console if the OS has booted up successfully. A bubble network is an isolated network which isn’t connected to any other network.
During the test, the source site continues to run normally, and any changes you make on the target site are discarded at the end of the test. If instead you want to shut down the source VMs and run the VMs on the secondary site, consider planned failover instead.
Understanding failover operations
There are two types of failover operations:
- Planned failover Use a planned failover when you want to move to your secondary site. Regulatory purpose might require this kind of failover, or you might need to prove that your business can operate normally when running on a secondary site. To plan this, open a ticket with Rackspace Technology.
- Unplanned failover Use an unplanned failover when an unexpected and adverse event occurs, and you need to fail over immediately. Call Rackspace Technology for help with executing an unplanned failover.
During a failover, source VMs are shut down (if they are not already down). To move back to the original site, you must first do a reverse protection.
To improve the RTO during recovery, you can start working even before the target VM volumes on the target Site have been fully synchronized. The system analyses every request and response returned from the Target VM directly or from the journal if the information in the journal is more current. This process continues until the recovery site virtual environment is fully synchronized, up to the chosen checkpoint when the integrity of the protected site was assured.
Understanding VM replication roles and responsibilities
The following list identifies the roles and responsibilities for Rackspace Technology VMware Server Virtualization VM replication:
- Rackspace Technology: Rackspace Technology is responsible for performing the task.
- Customer: Customer is responsible for performing the task.
- Rackspace Technology (Customer Initiated: Rackspace Technology is responsible for performing the task, but we expect the Customer to initiate the actions.
- Not Applicable: The task or option is not applicable to the selected edition.
Sizing
| TASK | LOCAL REPLICATION | REMOTE REPLICATION |
|---|---|---|
| Size customer-required infrastructure for local recoveries or failovers to the target site | Rackspace | Rackspace |
| Provide VM replication journal-sizing requirements | Rackspace | Rackspace |
Deployment
| TASK | LOCAL REPLICATION | REMOTE REPLICATION |
|---|---|---|
| Install VM replication management infrastructure at source and target site as needed | Rackspace | Rackspace |
| Pair source and target site as peers as needed | Not Applicable | Rackspace |
| Install VM replication virtual replication appliance on every customer-dedicated hypervisor at source and target site as needed | Rackspace | Rackspace |
Configuration
| TASK | LOCAL REPLICATION | REMOTE REPLICATION |
|---|---|---|
| Configure Rackspace network connection between source and target site as needed | Not Applicable | Rackspace |
| Configure default Virtual Protection Groups (VPG) | Rackspace | Rackspace |
| Customize networking and VPG configuration | Rackspace (Customer initiated) | Rackspace (Customer initiated) |
Testing and recovery
| TASK | LOCAL REPLICATION | REMOTE REPLICATION |
|---|---|---|
| Perform failover test operations | Rackspace (Customer initiated) | Rackspace (Customer initiated) |
| Perform local recovery operations | Rackspace (Customer initiated) | Not Applicable |
| Perform remove failover and move operations | Not Applicable | Rackspace (Customer initiated) |
| Complete database and application recovery after recovery or failover operations | Customer | Customer |
| Validate VMs are operating as expected after recovery or failover operations | Customer | Customer |
| Perform failback operations from target site to source site | Not Applicable | Rackspace (Customer initiated) |
Monitoring and management
| TASK | LOCAL REPLICATION | REMOTE REPLICATION |
|---|---|---|
| 24 x 7 monitoring of replication and investigate failures between source and target site | Rackspace | Rackspace |
| Perform incident resolution for VM replication management infrastructure | Rackspace | Rackspace |
| Perform maintenance on VM replication management infrastructure | Rackspace | Rackspace |
| Perform maintenance on VM replication management infrastructure including replication software upgrades | Rackspace | Rackspace |
| Escalation of incidents to technology vendor for software support or on-site resolution | Rackspace | Rackspace |
Understanding VM recovery
Rackspace Technology provides virtual machine recovery, which is a fully managed backup and recovery service, specifically for VMware Server Virtualization environments that are hosted in the Rackspace Technology data centers. Rackspace Technology Managed Backup and VMware’s API for Data Protection (VADP) powers VM recovery. It provides 24-hour RPO and 12-hour RTO.
This section contains the following topics:
- Understanding VM recovery key features
- Understanding VM recovery architecture
- Understanding VM recovery roles and responsibilities
- Understanding VM recovery technical requirements and limitations
Understanding VM recovery key features
VM recovery includes the following key features:
- Fully managed backup and recovery 24x7x365.
- VM image-level backup and recovery.
- Individual file-level backup and recovery.
- Database and application specific backup and recovery (using guest OS agents).
- 24-hour RPO and 12-hour RTO.
- Rackspace Technology initiation of restoration of customer data stored onsite within two hours of the time customer requests the restore via a support ticket.
- Rackspace Technology initiation of restoration of customer data stored offsite within six hours of the time customer requests the restore via a support ticket.
Providing the following benefits when compared to guest OS based technologies:
- Smaller backup window.
- Protected powered-off VMs.
- Reduced load on ESXi host and VMs.
- Increased recovery scenarios, providing VM image-level backup and recovery.
- Faster RTOs.
Rackspace Technology Customer Portal allows the customer to view backup configuration, status, and history. It also enables the customer to request backup policy changes and submit restore requests.
Understanding VM recovery architecture
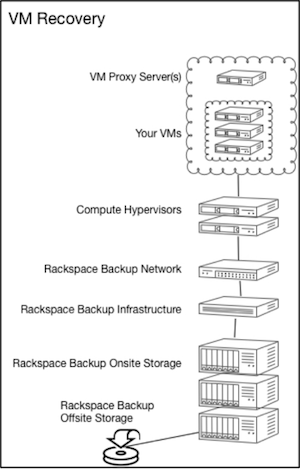
The following diagram illustrates the architecture of VM recovery:
Understanding VM recovery roles and responsibilities
The following table identifies the roles and responsibilities for the customer and Rackspace Technology.
| Category | Customer | Rackspace Technology |
|---|---|---|
| Backup | Defines the backup and recovery requirements for VMs and applications. | Implements the appropriate hypervisor proxies, VM configuration and application backup agents. |
| Monitoring | Monitors backup operations. | |
| Recovery | Requests full VM, individual file, or application-level recovery as needed. | Performs the recovery. |
Understanding VM recovery technical requirements and limitations
VM recovery is subject to the following technical requirements and limitations:
- Each hypervisor needs a VM recovery proxy.
- VMware datastores containing virtual machines need a minimum of 15% free space. VM backup jobs are stopped if less than 10% datastore space is available.
- Backup and restore times depend on the VM(s) size. VMs larger in size and smaller file counts experience a more extended backup and recovery time.
- We use client-based data de-duplication in order to reduce backup times.
If your VMs do not meet these requirements, then consider VM Replication Local Edition as an option.
Updated 8 months ago