
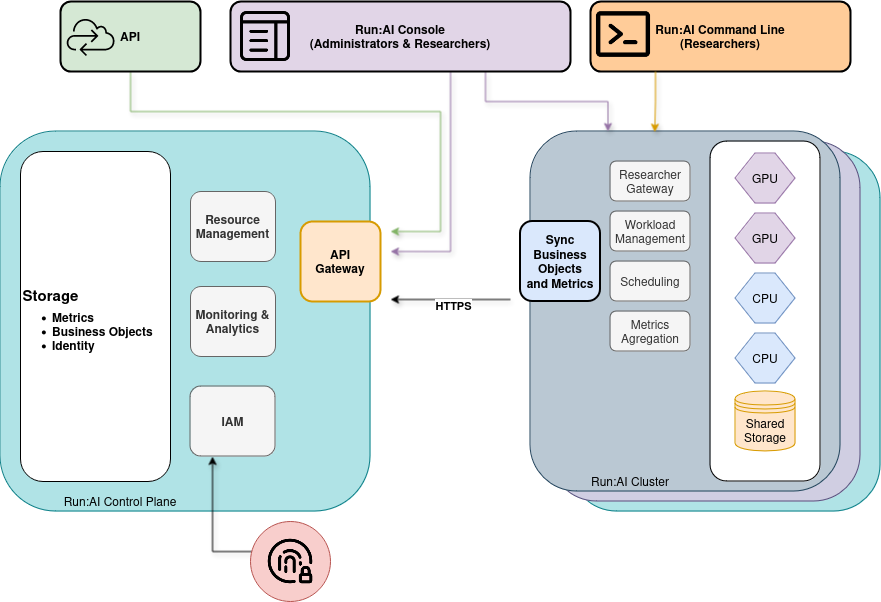
Run:AI - An overview
Run:AI's software platform is built on Kubernetes and is designed to orchestrate containerized AI workloads across GPU clusters. It allows different Deep Learning tasks, such as model development, training, and inference, to utilize the GPU compute resources dynamically, based on the requirements of each job.
The platform pools the available GPU resources and allocates them to jobs automatically, based on their compute needs. This approach aims to maximize the utilization of the GPU compute resources across different stages of the AI workflow.
Run:AI on YouTube
Visit to see available Tutorials on Run:AI made by Run:AI.
Run:AI Key features
Fair Resource Allocation
Run:AI's platform implements fair scheduling mechanisms to prevent resource contention. It enforces quota-based priorities and automatically preempts jobs when necessary, ensuring resources are fairly distributed across users and teams based on their allocated shares.
Intelligent Job Scheduling
Run:AI's platform utilizes job queues and opportunistic scheduling for batch jobs. This approach minimizes GPU idleness and maximizes cluster utilization by efficiently managing the execution order of jobs based on resource availability and priorities.
Controlled Resource Access
Run:AI's platform enforces guaranteed resource quotas for each user or group. This capability prevents scenarios where a single user or team monopolizes all available GPU resources. It ensures that every authorized entity has access to a minimum, pre-defined amount of GPU compute power at all times.
Efficient Resource Utilization
Run:AI's platform employs bin packing and workload consolidation techniques to optimize cluster utilization and mitigate fragmentation issues. It automatically packs jobs onto available resources in an efficient manner, ensuring that cluster capacity is maximized while minimizing underutilized pockets of resources.
Distributed Workload Orchestration
Run:AI's platform supports gang scheduling, enabling reliable execution of distributed workloads across multiple nodes within the cluster. This capability ensures that large, parallelized jobs that require coordinated allocation of resources on several machines can be scheduled and run seamlessly.
Updated 8 months ago