Understanding Server Virtualization
A virtual server runs inside a virtual machine (VM) instead of a physical machine. In VMs, the operating system (OS) layer does not link directly to the physical hardware layer. Instead, there is a layer between the OS and the physical layer, called a virtualization layer. A virtualization layer is sometimes known as an abstraction layer because it abstracts hardware from the OS.
You can run multiple VMs on a single server chassis. This configuration provides many benefits, including cost-effectiveness due to consolidation, less machine down-time, better resiliency, extra features such as snapshots, and easier migration and upgrades.
Instead of physical hardware, a VM uses virtual hardware such as virtual CPU (vCPU), virtual RAM (vRAM), virtual network interface card (vNIC), and virtual disks (vDisk) to complete operations. Because a single physical device can include multiple VMs, using VMs helps you to optimize hardware resources.
What is a virtual machine?
A VM is software that mimics the behavior of a stand-alone computer. You can use a VM to:
- Install an operating system.
- Install and run applications.
Understanding Hypervisors
A hypervisor is an OS that runs on a physical server and pools the available physical resources into the virtual resources that VMs require. You use a hypervisor to run and manage your VMs. This document refers to VMware ESXi™, which is a type of hypervisor. The word hypervisor can also refer to the physical machine on which ESXi is installed.
Understanding VMware vSphere Clusters
A VMware vSphere cluster is a collection of ESXi hypervisors that work together. vSphere cluster members pool their resources with a single VM that draws resources from one hypervisor at a time. All cluster members have either identical, or, in some cases similar, configurations.
By default, and to further benefit from the clustered setup, Rackspace Technology enables a Distributed Resource Scheduler and High Availability.
This section includes the following topics:
- Distributed resource scheduler
- High Availability
Distributed Resource Scheduler
Distributed Resource Scheduler (DRS) monitors the workload between hypervisors, and you can configure it to move VMs between ESXi hosts and address any imbalance automatically. Refer to Move a VM between two hosts or two datastores for more information about vMotion migration.
DRS operates in the following three modes:
- Fully automated (default, recommended): When you power on a VM, DRS moves running VMs and automatically selects the most suitable host.
- Partially automated: DRS automatically selects the most suitable host when you power on a VM but only provides recommendations to migrate running VMs.
- Manual: DRS provides recommendations for the initial placement of VMsand recommendations for running VMs but does not automatically migrate running VMs.
Because the vSphere Cluster uses workload to determine the placement of the VMs, the placement of VMs can appear random and not associated with your business requirements. To control VM placement, you can ask us to configure DRS rules.
Consider the following DRS rules categories:
- VM-VM Affinity: Keep VMs together. Use this affinity setting if VMs perform best when they run on the same host.
- VM-VM Anti-affinity: Keep VMs separate and prevent them from running on the same host. If you have two web servers running on the same host, and the host fails, both web servers go down.
- VM-Host rules: Host rules apply to a group of VMs and a group of hosts. Each group must include at least one member. Use the following options to define a VM-Host rule:
- A group of VMs should run on a group of hosts. This approach limits some VMs to run only on a set of hosts. You might want this option due to a specific hardware (for example, greater capability) advantage on those hosts. However, the rule is ignored when you place eligible hosts in maintenance mode and during an HA restart.
- A group of VMs must run on a group of hosts. VMs do not automatically migrate when you place all eligible hosts in maintenance mode. In addition, if no hosts in the defined group are available, HA might not restart the VMs.
- A group of VMs should not run on a group of hosts. This rule is similar to the first VM-host rule, except that this rule defines the group of hosts that some VMs should avoid. For example, VMs are not placed in a group of hosts that are defined as part of the rule.
- A group of VMs must not run on a group of hosts. The VMs avoid the specified hosts at all costs, even during an HA failover event.
High Availability
VMware vSphere® HA monitors the ESXi host status, and when a host fails, the vSphere HA feature automatically restarts the VMs on remaining hosts. For the HA feature to function as intended, the storage and networking must be consistent across all hosts in the vSphere cluster.
Understanding VMware vCenter
VMware vCenter® is a centralized server that Rackspace Technology uses to manage your VM environment.
Rackspace Technology Support uses the VMware vCenter user interface to connect to and manage your ESXi hosts. The Rackspace VMware Server Virtualization offering does not provide you access to VMware vCenter or a vSphere Client. If you require access to VMware vCenter, you can consider the VMware Server Virtualization Isolated vCenter deployment model.
Understanding vCPU
A VM includes one or more virtual central processing units (vCPU). By allocating vCPUs to VMs, you can share physical CPUs on the hypervisor with the VMs.
Over-allocating CPU can negatively impact system performance. You should only allocate as many vCPU resources as your VM needs. If you allocate more cores than you need, you waste CPU cycles that could be used by your other VMs.
Understanding vRAM
You can allocate physical RAM on the hypervisor to the VMs as virtual RAM (vRAM). If you allocate more vRAM than is physically installed, application performance can suffer because of the techniques that ESXi uses to reclaim memory, such as memory swapping and memory ballooning.
You should only allocate as many vRAM resources as your VM needs.
Understanding Networking
This section explains networking concepts that are important to understand when you use Rackspace Server Virtualization.
The following diagram illustrates virtual and physical networking components and their relationships to each other:
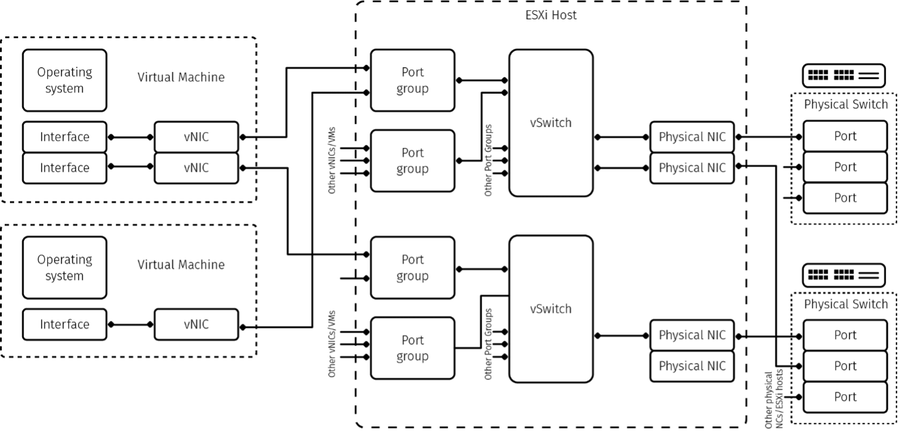
- Understanding vSwitches
- Understanding uplinks
- Understanding port groups
- Understanding vNICs
Understanding vSwitches
Within ESXi, a vSwitch is a virtual switch, which is a logical construct that provides a link between uplinks and port groups. A vSwitch can use multiple uplinks and manage multiple port groups.
If a vSwitch uses two or more uplinks, a vNIC can only use one uplink at a time. For example, if you have two 1000 Gbps uplinks connected to the vSwitch and your VM connected to the port group connected to that vSwitch, the maximum theoretical bandwidth for that VM is 1000 Gbps, rather than 2000 Gbps.
Your ESXi host usually has multiple vSwitches:
- A vSwitch that is connected to an external network (this is the primary connection for your VMs).
- A vSwitch that is connected to a dedicated backup network.
Understanding uplinks
An uplink is the physical interface between the hypervisor and the physical switch. An uplink is assigned to only one vSwitch. You can refer to an uplink as vmnicX, with X being a sequential number of a physical network ports on the hypervisor.
Understanding Port Groups
A port group is a logical construct on the vSwitch to which vNICs can connect. A port group typically has a name and a VLAN ID. You can see the port group name shown as a network in the VMware Server Virtualization section of the Rackspace Technology Customer Portal.
One port group can serve multiple vNICs.
Understanding vNICs
A vNIC, or virtual network interface card, is a piece of the VM’s virtual hardware. A vNIC provides an interface for the OS and connects to a port group.
There are multiple types of vNICs, such as E1000 or E1000E. We recommend using VMNXET3 for all VMs.
Understanding Storage
This section explains the following storage concepts that are important to understand when you use VMware Server Virtualization.
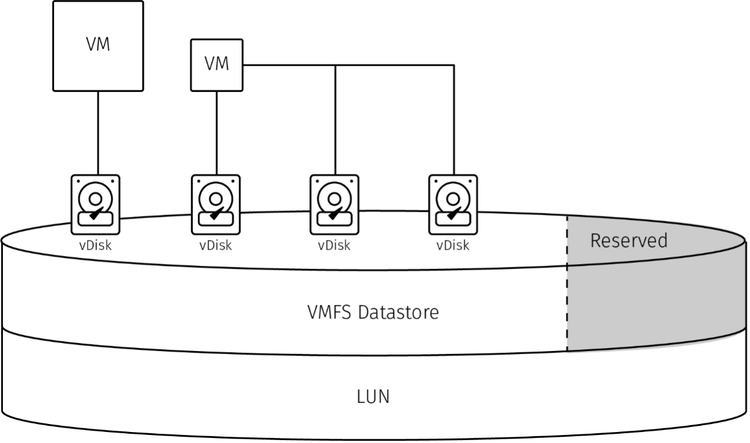
- Logical Unit Number (LUN): A LUN identifies a storage device. In the context of VMware, a LUN provides a foundation for a VMware filesystem (VMFS) datastore, or you can use it as an RDM (Raw Device Mapping)
- Datastore: A datastore is a volume formatted with a VMFS. You can create a VMFS datastore on top of a LUN or on a local RAID array. A VMFS datastore contains log files or files that comprise VMs.
- vDisk: A vDisk is a virtual disk. A Guest OS in the VM uses a vDisk in the same way it would use a physical disk but represents the vDisk as a .vmdk file on a VMFS datastore.
The following graphic illustrates VMs that are connected to vDisks of different sizes. The vDisks reside on a VMFS datastore with some of the datastore space reserved. The datastore is formatted on top of a LUN.
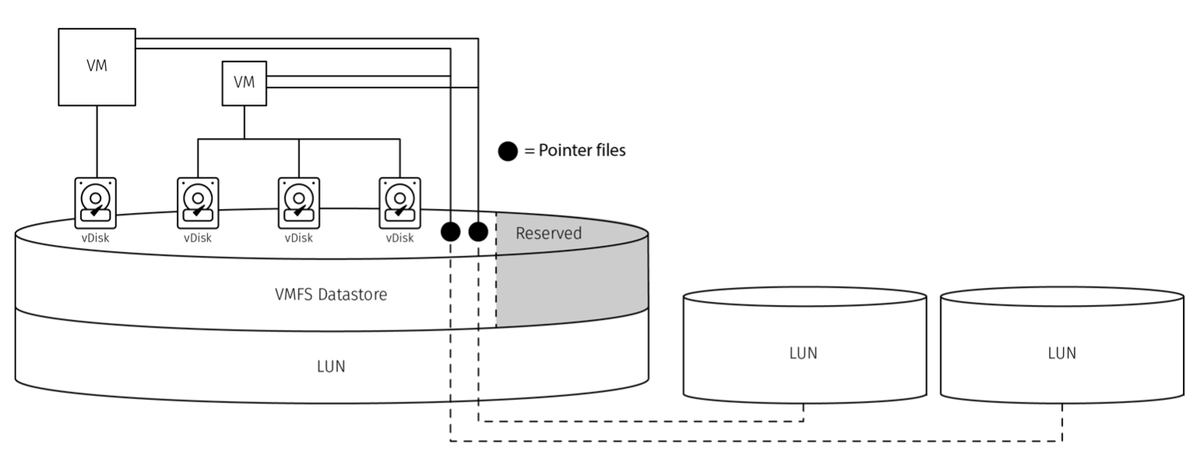
- Raw Device Mapping: Raw Device Mapping (RDM) is a type of storage configuration where a LUN is mounted to the VM directly, bypassing the datastore layer. Bypassing the datastore layer means that the Guest OS in the VM can issue Small Computer System Interface (SCSI) commands directly to the LUN. This configuration is most commonly used with Microsoft clustering. However, using RDMs means you cannot use features such as snapshots or VM-level backups. Other operations, such as storage vMotion, might also become more complex.
The following image illustrates two clustered VMs using their own vDisks and sharing two raw device LUNs. The pointer files, which reside on the VMFS Datastores alongside the vDisks, act as a proxy between the LUNs and the VMs.
Understanding Snapshots
A snapshot represents a point-in-time state of the VM. Snapshots are useful if you suspect a short-term rollback might be needed, such as before starting a software upgrade on your VM.
When you take a VM snapshot, a delta file is created for each vDisk, and all changes moving forward are written to the delta files. This operation happens in the background and is not exposed to the Guest OS.
The delta files can grow rapidly and without your awareness. If the delta files fill the datastore, your VM might pause, which can result in unexpected downtime. Monitor the free space on your datastores and delete all unneeded snapshots.
As snapshot files grow, it can affect all virtual machines on the hypervisor. For this reason, we recommend keeping a snapshot for no longer than two days.
Depending on the circumstances, you can delete snapshots within hours or days after being taken. When you delete the snapshot, the changes stored in the delta files are merged back onto the original vDisks. This operation can take a long time. You can also revert (roll back) to a snapshot, in which case the changes in the delta files are discarded.
Do not use a snapshot as a VM backup. VM replication is a better alternative for making and restoring backups.
Understanding Migrations
The following forms of migration are available depending on what you need to move:
- vMotion: vMotion is the technology that we use to migrate a VM from one ESXi host to another ESXi host. Depending on the circumstances, the migration can occur either offline or online. DRS uses vMotion automatically to balance the load between ESXi hosts. This form of migration happens either on a daily basis, often without your awareness as a result of automated action, or because you requested it. See Migrate a VM to a different ESXi host by using vMotion for more information.
- Storage vMotion: Storage vMotion migrates a VM from one VMFS datastore to another. The target datastore must have sufficient space. Storage vMotion migration can take a long time to complete, so your system might experience performance degradation during the migration operation. See Move a VM to a datastore by using storage vMotion for more information.
- vMotion without Shared Storage: vMotion without Shared Storage combines vMotion and storage vMotion. vMotion without Shared Storage is most commonly used for migration between two standalone hypervisors. See Migrate by using vMotion without shared storage for more information.
- Initial migration that occurs when you become a Rackspace Technology customer and migrate an existing workload to Server Virtualization. See Migrate a workload to VMware Server Virtualization for more information about migrating a workload from another environment to Server Virtualization.
Updated over 1 year ago