Patching
This section describes the necessary considerations and steps for patching guest Operating Systems in AWS services where the OS is unmanaged, focusing on EC2 instances.
Customers of Fanatical Support for AWS can reach out to the Rackspace support team for further advice, guidance, and assistance on applying security updates or patches to any of these services.
Patching guide for Amazon EC2
The guidelines on this page help you apply guest Operating System updates to Amazon Web Services (AWS) Elastic Compute Cloud (EC2) instances, covering both standalone instances and Auto-Scaling instances in a variety of common deployment models. We periodically update this document, so check back regularly or use this as a reference for your monthly patching cycle.
Automation artifacts
Rackspace recommends using Amazon-published Systems Manager (SSM) documents to manage and apply Operating System updates to standalone EC2 instances. This ensures a repeatable and automatable approach, reducing the possibility of inconsistencies or human errors that might occur when applying patches with direct management access, such as SSH or RDP, to instances.
For more information on Amazon-published Systems Manager documents, see Overview of SSM Documents for Patching Instances.
For customers seeking to patch their instances or Auto-Scaling Groups against the January 2018 Meltdown and Spectre vulnerabilities, find the Rackspace-developed SSM documents targeting Meltdown and Spectre patching and AMI generation on this page.
Instance categorization
Many organizations have a complex estate in AWS, comprising many different groups of EC2 instances. Guest Operating Systems (OS) running on EC2 come in two categories. The following decision diagram provides an overview of categorizing your EC2 instances and simplified steps for patching instances in both categories:
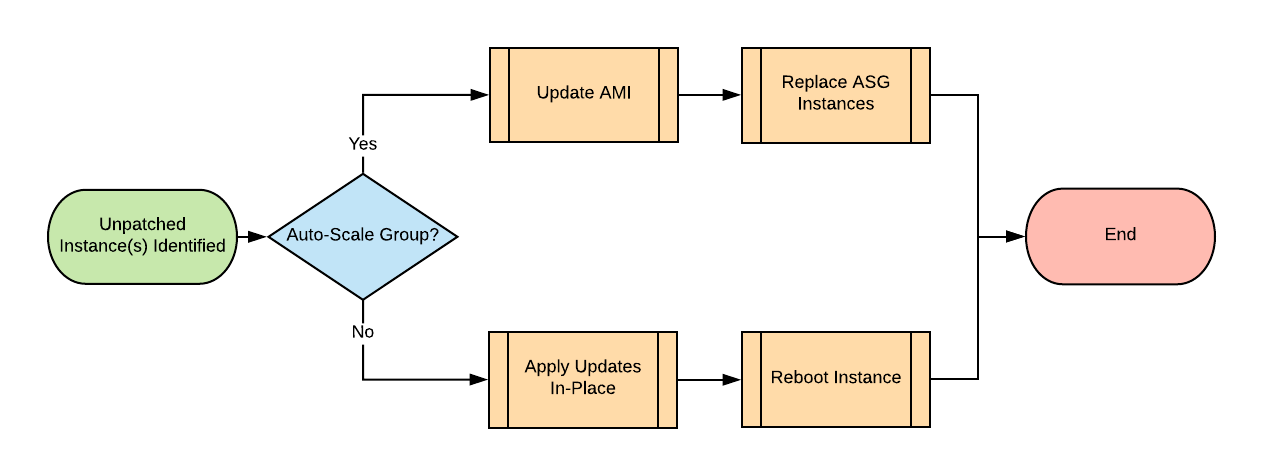
-
Standalone instances (not in an Auto Scaling Group)
- Method: Apply OS updates to these instances in place and reboot them.
- You normally provision standalone instances where the instance needs to be stateful. That is, it stores configuration or data locally, and you cannot replace it. An example would be a build server holding local configuration data.
- Auto-Recovery Instance often refers to standalone instances configured with CloudWatch Auto-Recovery alarms, improving resilience and availability. This guide treats these instances as simple Standalone instances.
-
Instances in an Auto Scaling Group (ASG)
- Method: Update the Amazon Machine Image (AMI) from which you launch these instances and perform a rolling replacement of the instances in each ASG.
- You normally provision ASG instances where an instance is stateless. That is, it stores all data externally (in S3 or a database), and you can replace the instance itself at any time. An example would be a group of web servers.
- ASG instances provide higher availability than Standalone instances and the potential to scale to tens or even hundreds of instances horizontally.
- New instances replace these instances regularly, whether or not you apply any Scaling Policies to your ASG. Patching existing ASG instances in place is therefore ineffectual.
- Don’t worry if you make manual changes to an ASG instance. This guide covers several corner cases in many different configurations.
Patching process overview
Generally speaking, if you have a group of identical web servers, you likely provision them in an ASG. You can examine each ASG (including a list of instances) in the AWS console by navigating to Services –> EC2 –> Auto Scaling –> Auto Scaling Groups.
On the other hand, you likely provision individual instances fulfilling utility roles as standalone instances.
If you are unsure or need to list or report on your instances programmatically, you can examine the tags on each instance. ASG instances have the aws:autosscaling:groupName tag key. This is an AWS-reserved tag that you cannot modify manually.
Following are some AWS CLI command examples:
- Describe all Auto Scaling instances in
us-east-1:aws --region=us-east-1 autoscaling describe-auto-scaling-instances
- List all Auto Scaling instances in
us-east-1, along with their ASG name and CloudFormation stack name:aws --region=us-east-1 ec2 describe-instances
--filters 'Name=tag-key,Values=aws:autoscaling:groupName'
--query 'Reservations[].Instances[].[InstanceId,Tags[?Key==`aws:autoscaling:groupName`],Tags[?Key==`aws:cloudformation:stack-name`]]' - List all standalone instances in
us-east-1, along with their CloudFormation stack name:aws --region=us-east-1 ec2 describe-instances
--query 'Reservations[*].Instances[?!not_null(Tags[?Key == `aws:autoscaling:groupName`])].[InstanceId,Tags[?Key==`aws:cloudformation:stack-name`]] | []'
After you identify whether you are dealing with a standalone instance or an Auto Scaling Group with one or more instances, you can use the following remediation process. Don’t worry if this looks intimidating at first. The majority of instances follow one of two simplified paths (one for Standalone, one for ASG instances), which we highlighted in red. We shaded in purple the automatable processes with the SSM documents:
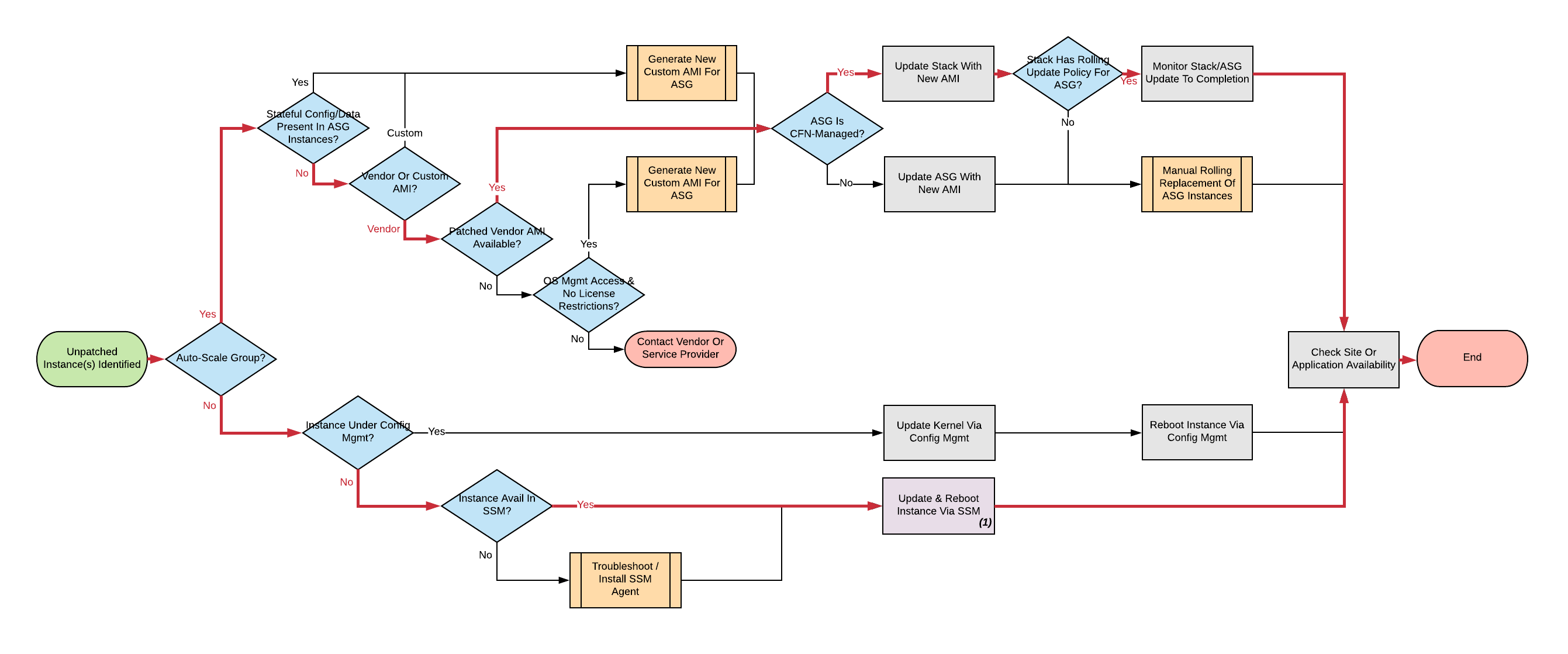
Click through for a larger version of this or any other image.
Standalone instances
You should patch standalone instances in place and reboot them.
If Configuration Management (examples: Puppet, Chef, Ansible, Saltstack) manages the instance, you should probably use this configuration management to apply updates and reboot. That’s all you need to do, so you can move on to the next instance.
If the instance is not under Configuration Management, you should apply the updates automatically by using Amazon Systems Manager, which is also known as Simple Systems Manager (SSM), or manually by using native OS tools if necessary.
Apply OS patches¶
You can find Systems Manager Patch Manager walkthroughs in the AWS Systems Manager User Guide.
If necessary, you can manually check and apply the updates, reboot the instance, and validate the update through your usual management access to this instance (SSH or RDP). However, Rackspace recommends using the Systems Manager Documents to ensure repeatability, eliminate manual work, and manage scheduling across your EC2 instance estate.
Amazon Systems Manager troubleshooting¶
If your instance is not available in Systems Manager, one of the following problems might be the cause:
-
The instance IAM role does not allow the instance to communicate with the Systems Manager API.
- You can update the instance role or role policies by using the AWS console, API, or CLI without any downtime to the instance.
- If you need to create a role or policy manually, see Create an Instance Profile Role for Systems Manager in the Amazon Systems Manager User Guide, or reach out to the Fanatical Support for AWS Support team for assistance.
-
The SSM Agent is not running on the instance.
- This requires you to access the instance (usually through SSH or RDP) and reinstall the agent.
- Find documentation on installing the SSM agent in the AWS Systems Manager User Guide
Auto Scaling Group instances
Update Auto Scaling Groups with a new Launch Configuration (LC) specifying a new AMI that incorporates the necessary OS updates. Then, replace them by using a rolling update to the ASG.
Update AMI
Update Auto Scaling Groups under CloudFormation management with a CloudFormation Stack Update.
Confirm CloudFormation management by checking the Auto Scaling Group tags for the aws:cloudformation:stack-name tag key. This is an AWS-reserved tag that you cannot modify manually.
Following are some AWS CLI command examples:
- List all ASGs in
us-east-1created by CloudFormation and their CloudFormation stack name:aws --region=us-east-1 autoscaling describe-auto-scaling-groups
--query 'AutoScalingGroups[?not_null(Tags[?Key == `aws:cloudformation:stack-name`])].[AutoScalingGroupName,Tags[?Key==`aws:cloudformation:stack- name`].Value] | []'
- List all ASGs in
us-east-1not created by CloudFormation:aws --region=us-east-1 autoscaling describe-auto-scaling-groups
--query 'AutoScalingGroups[?!not_null(Tags[?Key == `aws:cloudformation:stack-name`])].AutoScalingGroupName | []'
Almost all CloudFormation stacks use a template that allows you to enter the AMI ID as a parameter during the stack update by using the following steps:
- Navigate to AWS Console –> Services –> CloudFormation –> StackName –> Update Stack.
- Advance to the Specify Details stage and look for the AMI or ImageId parameter.
Only a few CloudFormation stacks hard-code the ImageId property of the AWS::AutoScaling::LaunchConfiguration resource, which the AWS::AutoScaling::AutoScalingGroup resource references in turn.
In that case, update these stacks by changing the ImageId property in the template and updating the stack with the new template.
If you have trouble updating a CloudFormation template or need to move towards best practices, such as parameterizing the AMI ID, then ask Rackspace for assistance.
If you change to a template, remember to check it into a version control repository, such as Git, that you use.
Update Auto Scaling Groups not under CloudFormation (or other Infrastructure as Code) management by creating a new Launch Configuration (LC) and manually applying it to the Auto Scaling Group by using the following steps:
-
Identify the current LC used for the ASG.
-
Create a copy of the LC with an updated AMI.
- Navigate to AWS Console –> Services –> EC2 –> Auto Scaling –> Launch Configurations.
- Select a LC –> Copy launch configuration.
- Click Edit AMI.
- Click Create launch configuration.
-
Edit the ASG and select the new LC.
Vendor AMI
If you are using a default vendor AMI with no baked-in customization, then update the ASG with the latest version of the vendor AMI. This guide provides the following references for your convenience, but you should always use the latest AMI issued by the vendor.
- Amazon Linux: AMI list
- Red Hat Enterprise Linux: How to list AMIs
- The Ubuntu operating system: AMI list
- CentOS Linux: How to list AMIs
- Microsoft Windows: AMI list
Generating a custom AMI
Under the following circumstances, you might need to generate a custom AMI for your ASG:
- The ASG is already using your own custom AMI, usually a descendant of an original vendor AMI.
- No updated vendor AMI is available.
- You have made manual changes to the ASG instances, usually by using direct SSH or RDP access, and you did not integrate these changes into the existing AMI, User Data, CloudFormation template, or Configuration Management.
You lose manual changes such as these when you replace the instances. This is a precarious situation because the instances might get replaced at any time, even outside this patching process. For example, an existing instance goes down, a routine scaling event occurs, and so on.
It is therefore critically important to integrate these changes by creating a new custom AMI.
The following process shows how to generate a custom AMI (if necessary). As before, we shaded automatable processes in purple. You can use SSM documents to automate new patching AMI generation, either from an existing AMI or an existing instance. For examples, see the Rackspace SSM documents targeting AMI generation for Meltdown/Spectre remediation.

If you cannot use the Rackspace-authored SSM documents, use the following manual steps:
-
If you made manual changes to ASG instances, you need to make a temporary AMI from one of the existing instances to capture these manual changes.
You can do this offline by using the
--rebootCLI argument or without choosingNo rebootin the console AMI generator wizard. This process ensures that the instance shuts down properly for a consistent filesystem snapshot. -
Deploy a temporary instance from either your current AMI, your vendor AMI, or the temporary AMI generated in step 1.
If you generated a temporary AMI in step 1, you can deregister it and remove the associated EBS snapshot now.
-
Patch this temporary instance as you would any standalone instance.
If the temporary instance is available in SSM, use the instructions under the preceding Apply OS patches section to update the instance by using SSM documents.
If the temporary instance is not available in SSM (for example, the AMI did not contain an installation of the SSM agent), you need to access the instance directly (SSH or RDP) and manually apply updates.
-
Prepare the temporary instance for AMI generation by removing data, configuration, and software that your ASG instance launch and bootstrapping code deploys.
Examples of items you may need to remove:
- SSH keys and other secrets
- Log files
- Application code
- Software agents
-
Generate an AMI from this temporary instance by using the AWS console, AWS CLI, or any third-party tool that can call the
CreateImageAPI function. -
Terminate the temporary instance.
Rolling replacement of instances
You update most ASGs by using CloudFormation, and the stack template contains a RollingUpdate UpdatePolicy for the ASG. In this case, CloudFormation manages the rolling replacement of your instances. It deploys a new instance, waits for it to pass ASG Health Checks, drains it, and terminates the old instance. Then, you see a message similar to the following in the stack Events after the stack update and can monitor the stack update to completion:
Rolling update initiated. Terminating 5 obsolete instance(s) in batches of
1, while keeping at least 4 instance(s) in service. Waiting on resource
signals with a timeout of PT20M when new instances are added to the
autoscaling group.
Manual rolling replacement
If CloudFormation does not manage the ASG or the CloudFormation stack template does not contain a RollingUpdate UpdatePolicy for the ASG, then you need to perform a manual rolling replacement of the instances in the ASG. The following diagram illustrates this process:

Alternatively, you might want to update the CloudFormation stack template to add an UpdatePolicy to the Auto Scaling Group resource, similar to the following example:
"UpdatePolicy": {
"AutoScalingRollingUpdate": {
"PauseTime": "20M",
"WaitOnResourceSignals": "true",
"SuspendProcesses": [
"ScheduledActions",
"ReplaceUnhealthy",
"AlarmNotification",
"AZRebalance"
],
"MaxBatchSize": "1",
"MinInstancesInService": "1"
}
}
Find more information and examples in the CloudFormation User Guide: AutoScalingGroup and UpdatePolicy.
In-place patching of ASG instances (emergency only)
You can patch or reboot EC2 instances running under an ASG in place by using the preceding SSM documents, but you should consider this as emergency mitigation only. You must follow the patch with an AMI update and rolling replacement of all instances as soon as possible. New instances launched at any time in the future are unpatched (even if automatic patching is enabled), and a configuration discrepancy occurs with any existing instances, which are in an untested configuration.
More information: The correct functioning of your application within a group of Auto-Scaling instances relies upon current running instances and instances launched at any future date having the same configuration. Because you made this configuration in several stages or layers (as shown in the following examples), synchronizing and adequately testing existing instances against the configuration for future instances can be very difficult and error-prone. As a best practice, Rackspace recommends that you update the underlying AMI and perform a rolling replacement of all Auto-Scaling instances, as described in this guide.
Instance launch configuration occurs in the following stages:
- AMI: An instance launches from the AMI in the Launch Configuration. Commonly, this is a plain vendor AMI or a customized silver or gold AMI pre-configured with some software packages or application code.
- Cloud-init: The EC2 service uses cloud-init to perform initial instance configuration. This includes resetting the OS configuration left in the AMI, setting up networking, deploying SSH keys, and so on.
- User Data: cloud-init then executes the User Data, often used to set up software repositories, configuration management agents, and so on.
- Bootstrapping: Installation and configuration of software packages, usually by using CloudFormation
cfn-initmetadata and your Configuration Management. - Application Deployment: Copying and testing your application code by using AWS CodeDeploy, Configuration Management, or another dedicated deployment agent.
Automation Artifacts for Patching Meltdown/Spectre
Rackspace has developed several Amazon Systems Manager documents to help automate patching and AMI generation tasks. For customers seeking to patch their instances or Auto-Scaling Groups against the January 2018 Meltdown and Spectre vulnerabilities, particularly useful documents are listed below. These can be leveraged as part of the process described in the Patching Guide for Amazon EC2 to patch vulnerable instances in place, or to generate patched AMIs from existing instances or AMIs.
Customers can download these from the direct links below.
-
FAWS-MeltdownSpectre-PatchRunningWinLinuxEC2
- Checks for presence of meltdown/spectre patch for Windows and Linux machines. Optionally apply patches also.
-
FAWS-MeltdownSpectre-PatchLinuxAMI
- Creates new patched AMI (Spectre/Meltdown) from Linux source AMI
-
FAWS-MeltdownSpectre-PatchWindowsAMI
- Creates new patched AMI (Spectre/Meltdown) from Windows source AMI
-
FAWS-MeltdownSpectre-PatchLinuxEC2toAMI
- Creates new patched AMI (Spectre/Meltdown) from running EC2 instance
-
FAWS-MeltdownSpectre-PatchWindowsEC2toAMI
- Creates new patched AMI (Spectre/Meltdown) from running Windows EC2 instance
Patching Amazon ECS
Rackspace’s recommended method for securing ECS clusters with current software updates is to update the environment to the latest available Amazon ECS-Optimized AMI. Following this, rotate (replace) the host instances following the methods described in the Patching Guide for Amazon EC2 document.
Patching AWS Batch
Managed Compute Environments
Rackspace’s recommended method for securing AWS Batch managed compute environments with current software updates is to create a new compute environment (defaults to the latest Amazon ECS-Optimized AMI, or rebuild a new custom AMI). This new compute environment can then be added to an existing AWS Batch job queue, and the old compute environment removed and deleted.
Unmanaged Compute Environments
For unmanaged compute environments, you manage your own compute resources as an ECS cluster, and should follow the Patching Amazon ECS guidelines to update the ECS cluster.
For more information, see Compute Environments in the AWS Batch User Guide.
Patching Amazon EMR
Recommended method
Rackspace recommends that you secure EMR clusters with current software updates by launching a new EMR cluster with the latest EMR release. EMR clusters should not have indefinite runtime and should terminate after a specific processing job (Transient clusters) or after a succession of jobs (Long-running clusters).
Note: If an EMR cluster uses a custom AMI, you should create a new AMI with the desired updates and launch a new EMR cluster with the new AMI. You cannot alter the AMI used for an EMR cluster after launch.
Alternative method
It is possible to manually patch cluster instances in place by using OS management access to the instances. This might be appropriate if an EMR cluster needs to remain provisioned for a recurring job, but security updates are critical. You should replace the EMR cluster by using the preceding recommended method at the next downtime window.
Note: Any new instances launched, either through scaling changes or self-healing, apply outstanding patches at launch.
Patching AWS Elastic Beanstalk
Rackspace’s recommended method for securing Elastic Beanstalk environments with current software updates is to update the environment in-place to the latest version of the environment’s platform. Elastic Beanstalk will update the Auto-Scaling Group and Launch Configuration with the new AMI version and will perform a rolling replacement of instances. For more information, see Updating Your Elastic Beanstalk Environment’s Platform Version and Elastic Beanstalk Supported Platforms.
Managed Platform Updates
Additionally, you may wish to enable managed platform updates, which can update the environment’s platform version inside a weekly maintenance window (not available for the .NET on Windows Server platform).
Patching AWS OpsWorks Stacks
Recommended Method
Rackspace’s recommended method for securing OpsWorks Stacks with current software updates is to replace the instances with new instances. New instances will have the latest set of security patches installed during bootstrapping. Once the new instances are online, the old instances can be deleted. For more detailed information on this or the alternative options listed below, see Managing Linux Security Updates in the AWS OpsWorks User Guide.
Alternative Methods
Additionally, you may wish to enable managed platform updates, which can update the environment’s platform version inside a weekly maintenance window (not available for the .NET on Windows Server platform).
Updated over 1 year ago